

One Sample Test of Proportions
Suppose we are interested in estimating the proportion of individuals in a population who have a certain trait. For instance, we might be interested in studying the proportion of children living near a lead smelter who have colic. The prevalence of colic in the general public is estimated to be as low as 7%. The data set "pbkiddat" contains information on a sample of children living near a lead smelter.
The PBKID Data Set
Rosner (Rosner, Fundamentals of Biostatistics, 1995) presents the data from an observational study which evaluated the effects of lead exposure on neurological and psychological function in children who lived near a lead smelter. Each child had his or her blood lead level measured twice, once in 1982 and again in 1983. These readings were used to quantify lead exposure. The control group (n=78) consisted of children whose blood lead levels were less than 40 ug/100mL in both 1982 and 1983, whereas the exposed group of children (n=46) had blood lead levels of at least 40 ug/100mL in either 1982 or 1983. We can use these data to make inferences on the general population of children living near a lead smelter.
Point estimate
We estimate the proportion, p, as:
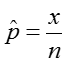
where x is the number in the sample who have the trait or outcome of interest, and n is the size of the sample.
Hypothesis Tests
- Null hypothesis H0: p= p0
- Alternative Hypothesis H1: p≠ p0
This hypothesis considers whether the population proportion is equivalent to some pre-specified value, p0. This value might be of historical interest or a result obtained in another study that we are trying to corroborate with our study data. A rule of thumb used to perform this test is that both np0 and n(1-p0) are greater than five.
To perform this test, we:
- Estimate the population proportion by the sample proportion,
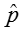 .
. - Calculate the following test statistic, which under the null hypothesis, follows approximately (dependent on the rule of thumb stated above) a Standard Normal Distribution:
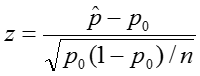
where n is the sample size.
Decision Rule:
Reject if Z > Zα/2, where Zα/2 is the 1-α/2 percentile of the standard normal distribution
Confidence Intervals
Additionally we can calculate confidence intervals for the sample proportion, again relying on the rule of thumb as stated above. The upper and lower limits of the confidence interval are given by:
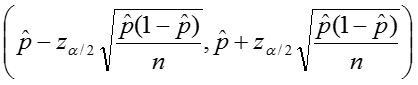
Example
In the pbkid data set there were 124 children and 23 of them had colic.
We can first estimate the proportion of colicky infants as:
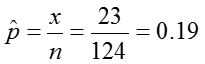
Using the information from the pbkid data set we can test if the prevalence of colic among children who live near lead smelter differs from that in the general public, which is around 7%.
Hypothesis:
- H0: The proportion of colic among children living near lead smelters is 0.07 (p= 0.07)
- H1: The proportion of colic among children living near lead smelters is not 0.07 (p≠ 0.07)
Significance Level: 0.05
Test Statistic:
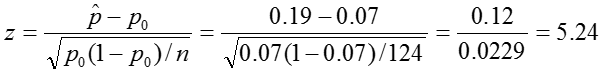
Decision Rule: Reject if |z| > 1.96.
Confidence interval:
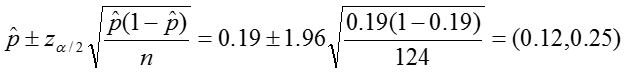
Conclusion:
In our sample, the proportion of colic among children living near lead smelters was 0.19. We calculated a z-statistic of 5.24 which is greater than the critical value, 1.96 associated with a significance level α = 0.05. Thus we reject the null hypothesis and conclude that the prevalence of colic among children living near lead smelters is different from 0.07. The 95% confidence interval is 0.12 to 0.25.