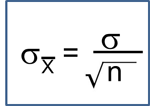



C. Confidence Intervals for the Odds Ratio
In case-control studies it is not possible to estimate a relative risk, because the denominators of the exposure groups are not known with a case-control sampling strategy. Nevertheless, one can compute an odds ratio, which is a similar relative measure of effect.6 (For a more detailed explanation of the case-control design, see the module on case-control studies in Introduction to Epidemiology).
Consider the following hypothetical study of the association between pesticide exposure and breast cancer in a population of 6, 647 people. If data were available on all subjects in the population the the distribution of disease and exposure might look like this:
|
|
Diseased |
Non-diseased |
Total |
|
Pesticide Exposure |
7 |
1,000 |
1,007 |
|
Non-exposed |
6 |
5,634 |
5,640 |
If we had such data on all subjects, we would know the total number of exposed and non-exposed subjects, and within each exposure group we would know the number of diseased and non-disease people, so we could calculate the risk ratio. In this case RR = (7/1,007) / (6/5,640) = 6.52, suggesting that those who had the risk factor (exposure) had 6.5 times the risk of getting the disease compared to those without the risk factor.
However, suppose the investigators planned to determine exposure status by having blood samples analyzed for DDT concentrations, but they only had enough funding for a small pilot study with about 80 subjects in total. The problem, of course, is that the outcome is rare, and if they took a random sample of 80 subjects, there might not be any diseased people in the sample. To get around this problem, case-control studies use an alternative sampling strategy: the investigators find an adequate sample of cases from the source population, and determine the distribution of exposure among these "cases". The investigators then take a sample of non-diseased people in order to estimate the exposure distribution in the total population. As a result, in the hypothetical scenario for DDT and breast cancer the investigators might try to enroll all of the available cases and 67 non-diseased subjects, i.e., 80 in total since that is all they can afford. After the blood samples were analyzed, the results might look like this:
|
|
Diseased |
Non-diseased |
|
|
Pesticide Exposure |
7 |
10 |
|
|
Non-exposed |
6 |
57 |
|
With this sampling approach we can no longer compute the probability of disease in each exposure group, because we just took a sample of the non-diseased subjects, so we no longer have the denominators in the last column. In other words, we don't know the exposure distribution for the entire source population. However, the small control sample of non-diseased subjects gives us a way to estimate the exposure distribution in the source population. So, we can't compute the probability of disease in each exposure group, but we can compute the odds of disease in the exposed subjects and the odds of disease in the unexposed subjects.