



Information Bias
Information bias occurs as a result of misclassification of exposure or disease status. The figure below shows a two-by-two contingency table in which smiley-face icons represent the findings instead of numbers. Subjects who truly have the health outcome of interest are shown with red icons, while those who truly did not develop the outcome are shown with blue icons. Subjects who have the exposure have a thick black outline, while the unexposed subjects do not. Based on this scheme it is apparent that most subjects are in the correct cell of the contingency table, but there are some who have been misclassified and are in an incorrect cell.
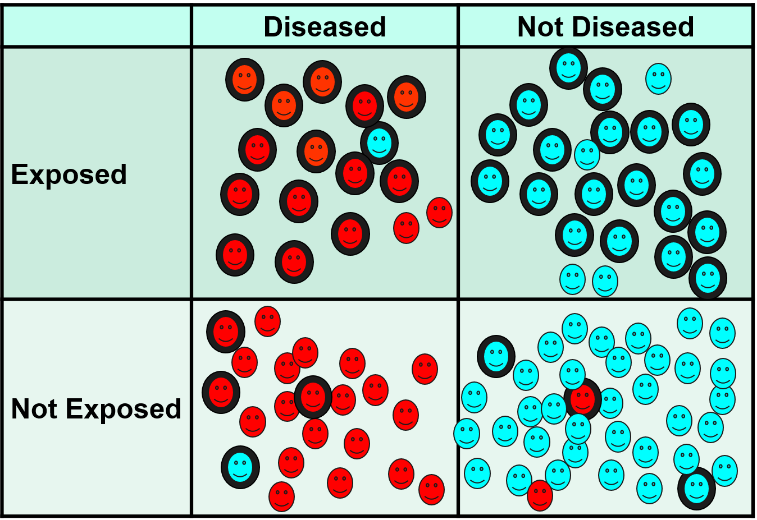
There are some non-diseased people who ended up in the diseased column, and there are some diseased people who were misclassified as non-diseased. In addition, some of those who were exposed were misclassified as unexposed, and some of the unexposed were misclassified as having been exposed. In general, misclassification of this type tends to be more of a problem for exposure status, but outcomes can be misclassified as well.
There are several mechanisms that produce misclassification, and the effects depend on the circumstances. The key distinction is whether the errors in classification are differential or non-differential with respect to the comparison groups.
Non-Differential Misclassification of Exposure
 Non-differential misclassification means that the percentage of errors is about equal in the two groups being compared. If there really is an association, non-differential misclassification tends to make the groups appear more similar than they really are, and it causes an underestimate of the association, i.e., "bias toward the null".
Non-differential misclassification means that the percentage of errors is about equal in the two groups being compared. If there really is an association, non-differential misclassification tends to make the groups appear more similar than they really are, and it causes an underestimate of the association, i.e., "bias toward the null".
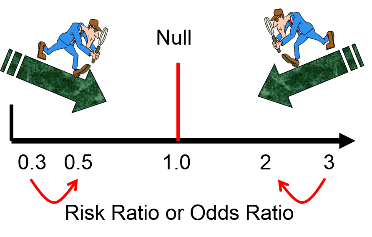
If the true risk ratio or odds ratio is 3, the biased estimate might be 2, and if the true risk ratio or odds ratio is 0.3, the biased estimate might be 0.5. In other words, regardless of whether the effect is an increase in risk or a decrease, non-differential misclassification moves the biased estimate toward the null value.
Mechanisms for Non-differential Misclassification
- Equally inaccurate memory of exposures in both groups. For example, in a case-control study of heart disease and past activity subjects have difficulty accurately remembering their exercise frequency, duration and intensity over many years. Note that in this scenario cases and controls are equally likely to report their past exercise levels inaccurately. If one group remembers better than the other, it will cause recall bias, which is differential. See Differential Misclassification in the next section.
- Recording and coding errors in records and databases. For example, many hospitals, insurance companies, and other agencies use codes for exposures, procedures, and diagnoses, such as the ICD-11 system (International Classification of Disease).
- Using surrogate measures of exposure. For example, using prescriptions for anti-hypertensive medications as an indication that the patient filled the prescription and actually took it regularly is often inaccurate.
- Non-specific or broad definitions of exposure or outcome. For example, if you are studying the effects of environmental tobacco smoke (ETS) exposure, asking whether a subject's spouse smokes will not capture where, when, and how often they smoke in the subject's presence or the subject's exposure to other sources of ETS, such as in the work place or other venues.
Example:
A case-control study used the diagnostic codes in a state-wide data base of hospital discharge data to estimate the association between diabetes and risk of coronary heart disease (CHD). The table below shows what the true association was.
| True | CHD | No CHD |
| Diabetes | 40 | 10 |
| No diabetes | 60 | 90 |
| 100 | 100 |
True OR= (40/10) / (60/90) = 6.0
However, diabetes was under-reported by about 50% in the computerized data base, and the collected data collected looked like this:
| Biased | CHD | No CHD |
|
Diabetes |
20 | 5 |
|
No diabetes |
80 | 95 |
| 100 | 100 |
Biased OR = (20/5) / (80/95) = 4.75
Differential Misclassification
 Differential misclassification occurs when data is more accurate in one of the comparison groups. Depending on the circumstances, differential misclassification can cause either an under-estimate or an over-estimate of the association. There are several mechanisms by which differential misclassification can occur.
Differential misclassification occurs when data is more accurate in one of the comparison groups. Depending on the circumstances, differential misclassification can cause either an under-estimate or an over-estimate of the association. There are several mechanisms by which differential misclassification can occur.
Recall Bias
Recall bias occurs when subjects in one of the compared groups recall past exposures more accurately than the other group. This is particularly a problem in case-control studies. Consider a case-control study by Louik et al. whose goal was to determine whether maternal use of anti-depressant medications during pregnancy is associated with an increased risk of congenital defects in the offspring. The use of anti-depressants during pregnancy was determined by interviewing mothers of children with congenital heart defects and mothers of normal children. The concern was that mothers who gave birth to a child with a congenital defect are likely to have repeatedly considered whether the defect was caused by something she took during pregnancy, while mothers of normal children are unlikely to have spent time trying to recall their use of medications during pregnancy. As a result, the exposure distribution might be underestimated in the the controls.
Louik et al. addressed this in their study and tried to maximize accuracy of recall in cases and controls by using a structured, multi-level interview described as follows:
|
"Using a multilevel approach, we first ask women whether they had any of a list of specific illnesses during pregnancy and what drugs they used to treat those conditions. We then ask about use of medications for specific indications, including "anxiety," "depression," and "other psychological conditions." Finally, independent of their responses to the previous questions, each woman is asked about her use of named medications, identified by brand name, including Prozac (fluoxetine), Zoloft (sertraline), Paxil (paroxetine), Effexor (venlafaxine), Elavil (amitriptyline), Celexa (citalopram), Luvox (fluvoxamine), Lexapro (escitalopram), and Wellbutrin (bupropion)." [Louik C, Lin AE, et al.: New England Journal of Medicine 2007:356; 2675-83]
|
The authors also addressed the issue of recall bias in the discussion of the paper:
|
"Recall bias may be a concern, since mothers of infants with malformations may recall and report exposures more completely than mothers of the control subjects who had no malformations. However, we consider this unlikely [in this study], since antidepressants are typically used on a regular basis for nontrivial indications, and recall of their use may be less subject to such bias than medications used infrequently and more casually. Further, the use of a multilevel structured questionnaire to identify medication use should minimize recall bias and has been shown to elicit rates of use similar to estimates from marketing data. Moreover, the null effects we observed among the non- SSRI antidepressants argue against recall bias, and recall bias would not explain risks associated with some individual SSRIs but not with others." [Louik C, Lin AE, et al.: New England Journal of Medicine 2007:356; 2675-83] |
Using Control Subjects With an Unrelated Diseased
Another technique for minimizing recall bias in a case-control study is to use diseased controls with a condition that does not have the same risk factors as the disease under study. For example, in a study of risk factors for atherosclerotic blockages in the arteries supplying the legs, the cases were patients who had had surgery to bypass an arterial blockage in a leg, and the controls were subjects who had undergone appendectomy. In this case, the risk factors for developing atherosclerosis are totally unrelated to the risk factors for needing an appendectomy. However, if diseased controls have a condition with the same risk factors as the disease under study, the association will be underestimated. This occurred in the classical case-control study of smoking and lung cancer conducted by Richard Doll and Austin Hill in 1948. They interviewed patients being treated for lung cancer in London hospitals and controls who were patients in the same hospitals being treated for conditions other than cancer. However, many of these controls had conditions such as heart disease and emphysema, for which smoking is a risk factor (although the investigators did not know this at the time). As a result, the exposure distribution in the controls was higher than in the source population, and the association between smoking and lung cancer, while significant, was underestimated.
NOTE: Recall bias is a differential misclassification that can cause either an over-estimate or under-estimate of association. In contrast, if cases and controls have equally inaccurate recall of past exposures, that is non-differential misclassification, not recall bias.
Interviewer Bias
If an interviewer has a pre-conceived notion about the hypothesis being tested, he or she might consciously or unconsciously interview case subjects differently than control subjects. For example, interviewers who believe that there is an association might question case subjects more rigorously and probe to a greater degree in order to encourage cases to recall a past exposure, while not prompting controls in the same way.
A variation on this can occur when exposure and outcome data are collected by reviewing medical records, particularly if definitions of exposures and outcomes are not explicit. If a reviewer believes that the research hypothesis was correct, the medical record of a case subject might be scrutinized more thoroughly to find evidence of exposure.
Methods for Minimizing Interviewer Bias
- "Blind" the interviewers if possible, i.e., don't tell them the research hypothesis or keep them from knowing whether subjects are cases or controls (This is not always possible).
- Use standardized questionnaires with close-ended, easy to understand questions and response options.
- For socially sensitive questions, e.g., alcohol & drug use or sexual behaviors, use a self-administered questionnaire instead of an interviewer.
- Train interviewers to adhere strictly to the question and answer format, with the same degree of questioning for both cases and controls.
- Verify the accuracy of data by examining pre-existing records (e.g., medical records or employment records) or assessing biomarkers.
Surveillance Bias
Surveillance bias (also known as detection bias or ascertainment bias) is a type of differential misclassification bias that may occur when subjects in one exposure group are more likely to have the study ourcome detected because they receive increased surveillance, screening or testing as a result of having some other medical condition for which they are being followed. For example, obese patients are more likely to undergo medical examinations, blood tests, and imaging studies than non-obese people. If obese subjects were being compared to non-obese subjects for risk of certain cancers, early cancers would be more likely to be found in the obese group, causing an overestimate of the true association. This type of bias can be minimized by selecting an unexposed group that receives a similar degree of scrutiny as the exposed group.