
PH717 Module 10 - Bias
Identifying and Preventing Bias
We have already alluded to sources of error in epidemiologic studies, and you have learned a number of methods for evaluating random error. We will now turn our attention to biases, i.e., systematic errors that are usually unwittingly introduced into a study by the investigators or the subjects that cause an over- or under-estimate of an association between an exposure and a health outcome.

In this module we will focus on selection bias and information bias.
By identifying common mechanisms of bias, we can design studies to limit these pitfalls, predict the impact of bias on our study results, and critically evaluate the published literature.
Essential Questions:
After completing this module, you will be able to:
The Key to Understanding Selection Bias
In all of the mechanisms that result in selection bias, there is over or under representation of one or more of the exposure-disease categories, i.e., one or more of the cells in the contingency table over or under represents what is true in the source population. As a result, the sample is not representative of the source population, and the estimate of association will be biased - either over-estimated or under-estimated.
|
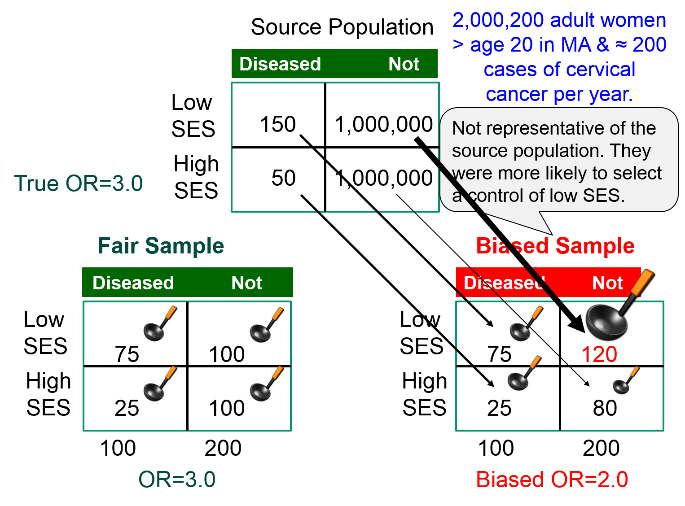
Suppose we wish to study the possible association between socioeconomic status (SES), defined based on current household income) and risk of cancer of the cervix. We have a source population with 2,000,200 women in whom there are 200 cases of cancer of the cervix during a calendar year.
If we studied all women in the source population and simply used the median household income to classify them as "higher" or "lower" SES, we would have found the exposure-disease distribution in the table below.
|
|
Cervical Cancer |
No Cancer |
|
Lower SES |
150 |
1,000,000 |
|
Higher SES |
50 |
1,000,000 |
The risk ratio and the odds ratio are both 3.0
However, we can't study the entire population, and since the outcome is relatively uncommon, we decide to do a case-control study. We begin by going to a large medical center that treats cervical cancer patients who are referred from all over the state and identify 100 patients with cervical cancer who agree to be interviewed. The interviews reveal that 75 of the women are from households with incomes that meet our definition of lower SES, and the other 25 are higher SES. To get non-disease control subjects, we send members of our research team into the neighborhood around the medical center and have them go door to door during the day to invite women to be interviewed as controls for our study. In many cases, no one seems to be home, but our team persists and eventually finds 200 control women, of whom 120 meet our definition of lower SES, and 80 who are of higher SES. The sample we have selected is summarized in the contingency table below, which is oriented to facilitate the use of the oddsratio.wald function in R.
|
|
No Cancer |
Cancer |
|
Higher SES (ref) |
80 |
25 |
|
Lower SES |
120 |
75 |
The analysis is performed as follows:
> ORtable<-matrix(c(80,120,25,75),nrow = 2,ncol = 2)
> oddsratio.wald(ORtable)
$data
Outcome
Predictor Disease1 Disease2 Total
Exposed1 80 25 105
Exposed2 120 75 195
Total 200 100 300
$measure
odds ratio with 95% C.I.
Predictor estimate lower upper
Exposed1 1 NA NA
Exposed2 2 1.172783 3.410692
$p.value
two-sided
Predictor midp.exact fisher.exact chi.square
Exposed1 NA NA NA
Exposed2 0.009913739 0.01048725 0.01023571
To summarize, the estimated odds ratio was 2.0; the 95% confidence interval for the odds ratio was 1.17 to 3.41; and the p-value was 0.01.
The result is statistically significant, but the estimated measure of association is biased. The odds ratio in the source population was 3.0, but the odds ratio in the biased sample was 2.0, i.e., there was bias toward the null. What went wrong?
The estimated OR was biased because counts in the contingency table for the sample were not representative of the exposure-disease distribution in the source population, which was the entire state. The cases, who were referred from all over the state did, in fact, indicate the exposure distribution in diseased women in the source population, i.e. 75 to 25 or 3:1. However, the exposure distribution among the 200 controls in the sample (120:80) was not representative of the exposure distribution in non-disease women in the source population (1:1). This occurred because the controls were selected by a different mechanism. By going door to door during working hours, the research team missed many women who were employed, so the sample over-selected women who were unemployed. Therefore, there was a greater tendency to select non-diseased controls of lower SES.
|
The key thing to remember here is that one of the four cells in my contingency table was over-sampled (and one was under sampled).
|
The figure below summarizes this scenario, showing the distribution in the source population at the top, the contingency table for the biased sample at the lower right, and the contingency table from a fair sample at the lower left. We have used images of ladles to represent the relative sampling for the contingency tables at the bottom. The representative sample has ladles in each of the four cells that are of equal size indicating a proportionate sample that is representative of the distributions in the source population. However, the biased sample at the lower right has a larger ladle for the non-diseased controls of lower SES, who were over-sampled because of the enrollment method used for the controls, and the controls of higher SES were therefore under sampled, as shown by a smaller ladle.
 Test Yourself
Test Yourself
Hemifacial microsomia is a rare congenital malformation in which the lower half of one side of the face is underdeveloped and does not grow normally. The condition varies in severity and is sometimes subtle and only recognized by an astute pediatrician. Affected children can be referred for surgery to improve facial symmetry by reconstructing the bony and soft tissues, but the surgery is only done in certain large medical centers that receive referrals from all over the United States.
Researchers wanted to study whether maternal smoking or maternal diabetes are associated with the risk of this condition in their offspring. The names of children treated for this problem were obtained from a medical center in Michigan that specializes in this type of corrective surgery. How can they identify control subjects in a way that avoids selection bias? [Hint: How can they ensure that the "would criterion" is met?] Think about this for a few minutes, and try to devise an unbiased sampling strategy for controls before you look at how the investigators achieved this.
Answer
Selection bias can be introduced into case-control studies with low response or participation rates if the likelihood of responding or participating is related to both the exposure and outcome.
Example:
A case-control study explored an association between family history of heart disease (exposure) and the presence of heart disease in subjects. Volunteers for "a study on heart disease" were recruited from an HMO, but what if subjects with heart disease were more likely to participate if they had a family history of heart disease? If a random selection of 1,000 members of the HMO had been invited to participate and all of them did, then the true odds ratio would have been 2.25 based on the counts in the first table below.
| True Association |
CHD |
No CHD |
|
Family History |
300 |
200 |
|
No Family History |
200 |
300 |
Therefore, the true OR= (3/2)/(2/3) = 2.25
However, suppose the response rates were only 60%, except for those with CHD and a family history, who might have been more likely to participate since they were curious about whether there was an association. Once again, the observed frequencies, shown in the next table, would not have reflected the distribution in the source population, and the resulting odds ratio would be biased.
|
Biased Association |
CHD |
No CHD |
|
Family History |
240 ( 80% ) |
120 (60%) |
|
No Family History |
120 (60%) |
180 (60%) |
The biased OR = (240/120)/(120/180) = 3.0
The only was to avoid this type of bias is to achieve high participation rates. The closer one gets to 100% participation, the less likely it is that this bias will affect the results. Participation of 80% or more of those invited is usually sufficient.
If participation is different by exposure status, but not by disease status, the result is not biased. We can illustrate this using the example above in which the unbiased OR = 2.25.
|
(Not Biased) |
CHD |
No CHD |
|
Family History |
240 ( 80% ) |
160 ( 80% ) |
|
No Family History |
120 (60%) |
180 (60%) |
Here, the participation differed between the two exposure categories, but within each exposure category participation was similar for the cases and the controls. As a result, the OR=2.25 (not biased).
Similarly, if participation differs by disease status, but not by exposure status, the result will not be biased.
|
(Not Biased) |
CHD |
No CHD |
|
Family History |
240 ( 80% ) |
120 (60%) |
|
No Family History |
160 ( 80% ) |
180 (60%) |
Here, the participation differed between the two outcome categories, but within each outcome category participation was similar for the exposure groups. As a result, the OR=2.25 (not biased).
Test Yourself
Researchers conducted a case-control study to determine whether maternal use of anti-depressant medications during pregnancy was associated with a higher risk congenital heart defects in their offspring. Mothers who recently had a baby are asked to participate in the study, and they were told what the research hypothesis was.
Could there be selection bias here? Think about this before looking at the answer below.
Answer
In the previous examples selection bias occurred because selection or enrollment procedures resulted in over- or under-representation of one or more of the exposure-disease categories. Since prospective cohort studies enroll subjects who have not yet developed the health outcomes of interest, selection bias due to enrollment procedures is rare, but can occur. In addition, prospective cohort studies can have selection bias as a result of differential retention during follow up.
Blood clots that form in the deep veins in the leg can break loose from the venous system and be carried back to the right side of the heart and then to the pulmonary artery where they become lodged and disrupt pulmonary circulation. This is referred to as pulmonary thromboembolism. It is a serious and sometimes fatal event, and some oral contraceptives (OC) have been shown to increase the risk of thrombosis (clot formation in the veins), particularly in older formulations of oral contraceptives.
Consider a hypothetical prospective cohort study of the association between use of oral contraceptives (OC) and development of pulmonary thromboembolism (TE) in women of child-bearing age, as summarized in the figure below. The contingency table at the top shows what the results would have been if there had been complete follow up. There are 10,000 subjects in each group, and 20 out of 10,000 OC users developed TE compared to 10 out of 10,000 women who did not use OC, so the true RR=2.0.
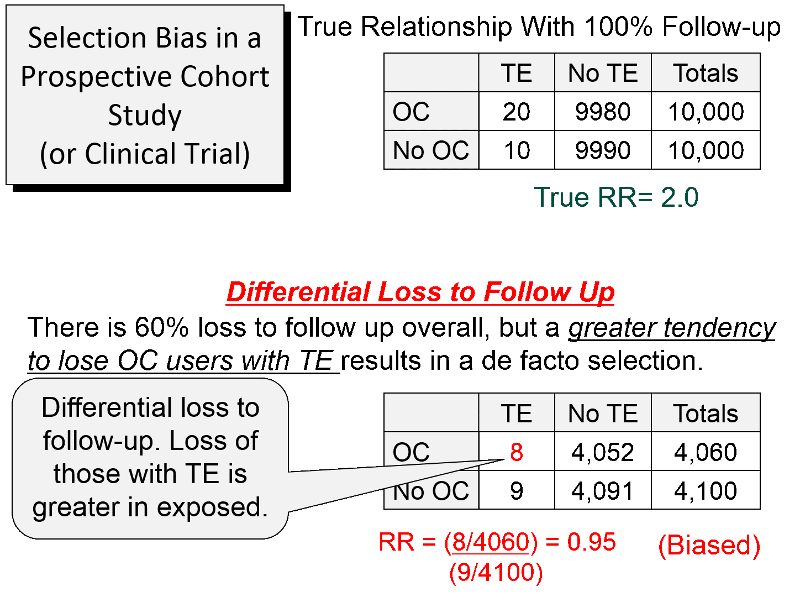
About 60% of the subjects were lost to follow up, as shown in the lower portion of the figure. However, there was differential loss to follow up, since 12 out the 20 women with TE were lost in the OC groups, but only one out of the 10 women with TE in the group not using OCs were lost. In the case-control study discussed above there was over-representation in one of the cells of the table, but here there is under-representation because of greater loss to follow up in women who had both the exposure and the outcome of interest. So, in this prospective cohort study, the sample that is available for analysis is not representative of the source population of women of child-bearing age. The result is a biased estimate from the sample which gives RR=0.95, suggesting no association, even though there is a two-fold increase in risk.
This form of selection bias (bias from differential loss to follow up) can occur in both prospective cohort studies and clinical trials if there are substantial losses to follow up. There is no way of knowing whether loss to follow up is differential, but if follow up rates are greater than 80%, the effects of this form are selection bias are likely to be minimal. The only way to avoid this type of bias is for investigators to do whatever they can to maintain high rates of follow up. If loss to follow up is much greater than 20%, one needs to be increasingly concerned that the estimate might be biased.
In a retrospective cohort study selection bias occurs if selection of either exposed or non-exposed subjects is somehow related to the outcome. For example, if researchers are more likely to enroll an exposed person if they have the outcome of interest, the measure of association will be biased.
Example:
Researchers wanted to conduct a retrospective cohort study on the health effects of an occupational exposure to an organic solvent in a factory using employee health records. The truth is that those exposed to the solvent had a two-fold increase in liver damage, and if they had had all of the records, the contingency table would have looked like the table below.
|
True |
Diseased |
Non-diseased |
Total |
|
Exposed |
100 |
900 |
1000 |
|
Unexposed |
50 |
950 |
1000 |
RR= (100/1,000)/(50/1,000) = 2.0
Unfortunately, many of the employee records had been lost or destroyed over the past 20 years. However, there had been suspicions about the health effects of the solvent for many years, and the records of employees who had been exposed and developed health problems were more likely to have been retained. Records were available for 98% of the employees who had been exposed and developed liver damage, but for all other employees only 80% of the records could be found. As a result, the contingency table looked like this.
|
Biased |
Diseased |
Non-diseased |
Total |
|
Exposed |
98 |
720 |
818 |
|
Unexposed |
40 |
760 |
800 |
RR= (98/818)/(40/800) = 2.4
Here, the source population consisted of the employees of the factory, and once again, the data in the sample was not representative of the source population. Specifically, one exposure-disease category had greater retention of records than the others, so the measure of association was biased. In a sense, loss of records in this retrospective cohort study is analogous to differential loss to follow up in prospective cohort studies and clinical trials.
The general population is sometimes used as a non-exposed comparison group in occupational studies of mortality, since data is readily available, and the general population is mostly unexposed to rare occupational exposures. The main disadvantage is that an employed work force tends to be generally healthier than the general population, because the general population also includes people who cannot work due to disease or disability. Consequently, the risk ratio for death will tend to be underestimated, when the higher risk general population is used as a surrogate for an unexposed work force; this is called "the healthy worker effect". Here, the source population is an employed work force, and death rates in the general population are not necessarily indicative of death rates in an unexposed work force.
Example:
Suppose an employed work force with a particular occupational exposure has an age-adjusted death rate of 130 per 100,000 workers, and the age-adjusted death rate in a very comparable employed work force that was unexposed was 100 per 100,000. In other words, the true risk ratio is 1.3.
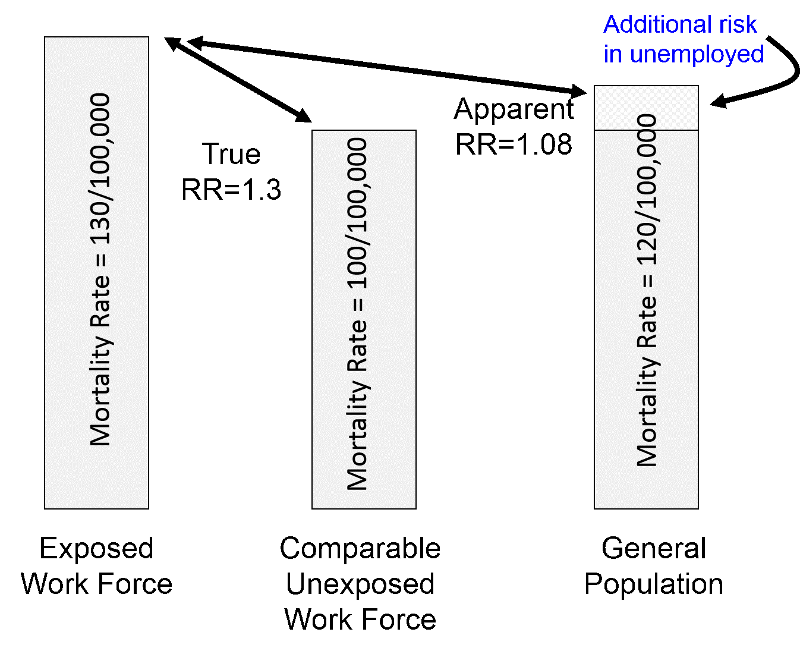
However, the age-adjusted death rate in the general population (which is mostly unexposed to rare occupational exposures) would tend to be higher than that of an unexposed work force, perhaps 120 per 100,000 because of a wide variety of illnesses and disabilities. Using the general population as surrogate for an unexposed work force would result in a risk ratio of 130/120 = 1.08, i.e., an underestimate of the true magnitude of association.
Selection bias occurs when selection, enrollment, or retention of subjects is differential for one of the exposure-disease categories. This can occur in any of the analytic studies, and it can cause either an overestimate or an underestimate of the measure of association.
In case-control studies selection bias can occur due to:
In cohort studies selection bias can occur due to:
Information bias occurs as a result of misclassification of exposure or disease status. The figure below shows a two-by-two contingency table in which smiley-face icons represent the findings instead of numbers. Subjects who truly have the health outcome of interest are shown with red icons, while those who truly did not develop the outcome are shown with blue icons. Subjects who have the exposure have a thick black outline, while the unexposed subjects do not. Based on this scheme it is apparent that most subjects are in the correct cell of the contingency table, but there are some who have been misclassified and are in an incorrect cell.
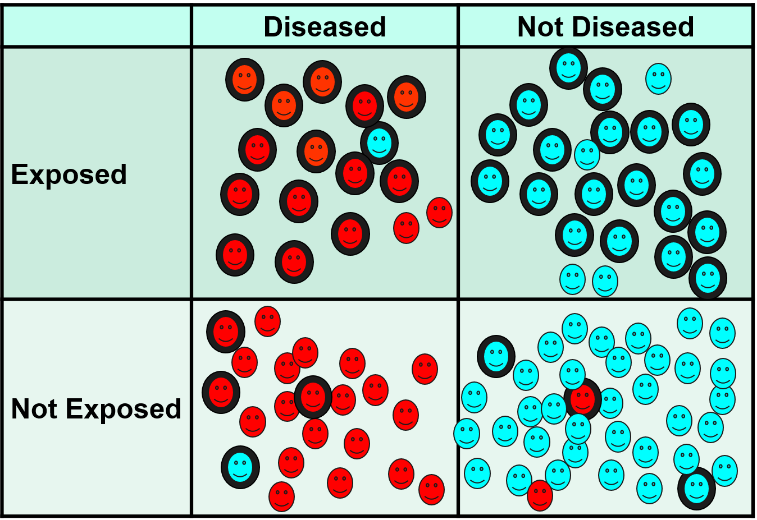
There are some non-diseased people who ended up in the diseased column, and there are some diseased people who were misclassified as non-diseased. In addition, some of those who were exposed were misclassified as unexposed, and some of the unexposed were misclassified as having been exposed. In general, misclassification of this type tends to be more of a problem for exposure status, but outcomes can be misclassified as well.
There are several mechanisms that produce misclassification, and the effects depend on the circumstances. The key distinction is whether the errors in classification are differential or non-differential with respect to the comparison groups.
 Non-differential misclassification means that the percentage of errors is about equal in the two groups being compared. If there really is an association, non-differential misclassification tends to make the groups appear more similar than they really are, and it causes an underestimate of the association, i.e., "bias toward the null".
Non-differential misclassification means that the percentage of errors is about equal in the two groups being compared. If there really is an association, non-differential misclassification tends to make the groups appear more similar than they really are, and it causes an underestimate of the association, i.e., "bias toward the null".
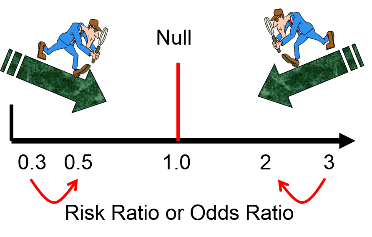
If the true risk ratio or odds ratio is 3, the biased estimate might be 2, and if the true risk ratio or odds ratio is 0.3, the biased estimate might be 0.5. In other words, regardless of whether the effect is an increase in risk or a decrease, non-differential misclassification moves the biased estimate toward the null value.
Example:
A case-control study used the diagnostic codes in a state-wide data base of hospital discharge data to estimate the association between diabetes and risk of coronary heart disease (CHD). The table below shows what the true association was.
| True | CHD | No CHD |
| Diabetes | 40 | 10 |
| No diabetes | 60 | 90 |
| 100 | 100 |
True OR= (40/10) / (60/90) = 6.0
However, diabetes was under-reported by about 50% in the computerized data base, and the collected data collected looked like this:
| Biased | CHD | No CHD |
|
Diabetes |
20 | 5 |
|
No diabetes |
80 | 95 |
| 100 | 100 |
Biased OR = (20/5) / (80/95) = 4.75
 Differential misclassification occurs when data is more accurate in one of the comparison groups. Depending on the circumstances, differential misclassification can cause either an under-estimate or an over-estimate of the association. There are several mechanisms by which differential misclassification can occur.
Differential misclassification occurs when data is more accurate in one of the comparison groups. Depending on the circumstances, differential misclassification can cause either an under-estimate or an over-estimate of the association. There are several mechanisms by which differential misclassification can occur.
Recall bias occurs when subjects in one of the compared groups recall past exposures more accurately than the other group. This is particularly a problem in case-control studies. Consider a case-control study by Louik et al. whose goal was to determine whether maternal use of anti-depressant medications during pregnancy is associated with an increased risk of congenital defects in the offspring. The use of anti-depressants during pregnancy was determined by interviewing mothers of children with congenital heart defects and mothers of normal children. The concern was that mothers who gave birth to a child with a congenital defect are likely to have repeatedly considered whether the defect was caused by something she took during pregnancy, while mothers of normal children are unlikely to have spent time trying to recall their use of medications during pregnancy. As a result, the exposure distribution might be underestimated in the the controls.
Louik et al. addressed this in their study and tried to maximize accuracy of recall in cases and controls by using a structured, multi-level interview described as follows:
|
"Using a multilevel approach, we first ask women whether they had any of a list of specific illnesses during pregnancy and what drugs they used to treat those conditions. We then ask about use of medications for specific indications, including "anxiety," "depression," and "other psychological conditions." Finally, independent of their responses to the previous questions, each woman is asked about her use of named medications, identified by brand name, including Prozac (fluoxetine), Zoloft (sertraline), Paxil (paroxetine), Effexor (venlafaxine), Elavil (amitriptyline), Celexa (citalopram), Luvox (fluvoxamine), Lexapro (escitalopram), and Wellbutrin (bupropion)." [Louik C, Lin AE, et al.: New England Journal of Medicine 2007:356; 2675-83]
|
The authors also addressed the issue of recall bias in the discussion of the paper:
|
"Recall bias may be a concern, since mothers of infants with malformations may recall and report exposures more completely than mothers of the control subjects who had no malformations. However, we consider this unlikely [in this study], since antidepressants are typically used on a regular basis for nontrivial indications, and recall of their use may be less subject to such bias than medications used infrequently and more casually. Further, the use of a multilevel structured questionnaire to identify medication use should minimize recall bias and has been shown to elicit rates of use similar to estimates from marketing data. Moreover, the null effects we observed among the non- SSRI antidepressants argue against recall bias, and recall bias would not explain risks associated with some individual SSRIs but not with others." [Louik C, Lin AE, et al.: New England Journal of Medicine 2007:356; 2675-83] |
Using Control Subjects With an Unrelated Diseased
Another technique for minimizing recall bias in a case-control study is to use diseased controls with a condition that does not have the same risk factors as the disease under study. For example, in a study of risk factors for atherosclerotic blockages in the arteries supplying the legs, the cases were patients who had had surgery to bypass an arterial blockage in a leg, and the controls were subjects who had undergone appendectomy. In this case, the risk factors for developing atherosclerosis are totally unrelated to the risk factors for needing an appendectomy. However, if diseased controls have a condition with the same risk factors as the disease under study, the association will be underestimated. This occurred in the classical case-control study of smoking and lung cancer conducted by Richard Doll and Austin Hill in 1948. They interviewed patients being treated for lung cancer in London hospitals and controls who were patients in the same hospitals being treated for conditions other than cancer. However, many of these controls had conditions such as heart disease and emphysema, for which smoking is a risk factor (although the investigators did not know this at the time). As a result, the exposure distribution in the controls was higher than in the source population, and the association between smoking and lung cancer, while significant, was underestimated.
NOTE: Recall bias is a differential misclassification that can cause either an over-estimate or under-estimate of association. In contrast, if cases and controls have equally inaccurate recall of past exposures, that is non-differential misclassification, not recall bias.
If an interviewer has a pre-conceived notion about the hypothesis being tested, he or she might consciously or unconsciously interview case subjects differently than control subjects. For example, interviewers who believe that there is an association might question case subjects more rigorously and probe to a greater degree in order to encourage cases to recall a past exposure, while not prompting controls in the same way.
A variation on this can occur when exposure and outcome data are collected by reviewing medical records, particularly if definitions of exposures and outcomes are not explicit. If a reviewer believes that the research hypothesis was correct, the medical record of a case subject might be scrutinized more thoroughly to find evidence of exposure.
Methods for Minimizing Interviewer Bias
Surveillance bias (also known as detection bias or ascertainment bias) is a type of differential misclassification bias that may occur when subjects in one exposure group are more likely to have the study ourcome detected because they receive increased surveillance, screening or testing as a result of having some other medical condition for which they are being followed. For example, obese patients are more likely to undergo medical examinations, blood tests, and imaging studies than non-obese people. If obese subjects were being compared to non-obese subjects for risk of certain cancers, early cancers would be more likely to be found in the obese group, causing an overestimate of the true association. This type of bias can be minimized by selecting an unexposed group that receives a similar degree of scrutiny as the exposed group.
Test Yourself
A study reported a risk ratio of 2.5 for the association between current or past smoking and coronary heart disease. A reviewer who critiqued the study pointed out that there could have been substantial non-differential misclassification of smoking exposure, and she argued that there may have been no association, i.e., that the RR=2.5 could have been due entirely to misclassification.
Answer
Test Yourself
A case control study was conducted to determine if using antihistamines around the time of conception increased the risk of birth defects in the offspring. No personal interviews were conducted regarding subjects' antihistamine use. Instead, women were considered exposed if computerized pharmacy records from their HMO indicated that they had filled at least one prescription for antihistamines within 500 days before the birth of the child. This method of ascertaining exposure has the advantage of avoiding recall bias, but could it introduce any other type of bias?
Answer
Test Yourself
A prospective cohort study was conducted to determine the risk of heart attack among men with varying levels of baldness. Third-year residents in dermatology conducted visual baldness assessments at the start of the study (before any heart attacks occurred). Four levels of baldness were coded: none, minimal, moderate, and severe. The follow-up rate was close to 100%. Could any of the following types of bias have occurred in this study?
Answer