


Evaluating Screening Programs
Even if a test accurately and efficiently identifies people with pre-clinical disease, its effectiveness is ultimately measured by its ability to reduce morbidity and mortality of the disease. The most definitive measure of efficacy is the difference in cause-specific mortality between those diagnosed by screening versus those diagnosed by symptoms. There are several study designs which can potentially be used to evaluate the efficacy of screening.
These include correlational studies that examine trends in disease-specific mortality over time, correlating them with the frequency of screening in a population. However,1) these are measures for entire populations, and cannot establish that decreased mortality is occurring among those being screened; 2) one cannot adjust for confounding; and 3) one cannot determine optimal screening strategies for subsets of the population.
Case-control and cohort studies are frequently used to evaluate screening, but their chief limitation is that the study groups may not be comparable because of confounders, volunteer bias, lead-time bias, and length-time bias.
Because of these limitations, the optimal means of evaluating efficacy of a screening program is to conduct a randomized clinical trial (RCT) with a large enough sample to ensure control of potential confounding factors. However, the costs and ethical problems associated with RCTs for screening can be substantial, and much data will continue to come from observational studies. Screening programs also tend to look better than they really are because of several factors:
Self-Selection Bias
People who choose to participate in screening programs tend to be healthier, have healthier lifestyles, and they tend to adhere to therapy better, and their outcomes tend to be better because of this. However, volunteers may also represent the "worried well," i.e., people who are asymptomatic, but at higher risk (e.g., relatives of women with breast cancer). All of these factors can bias the apparent benefit of screening.
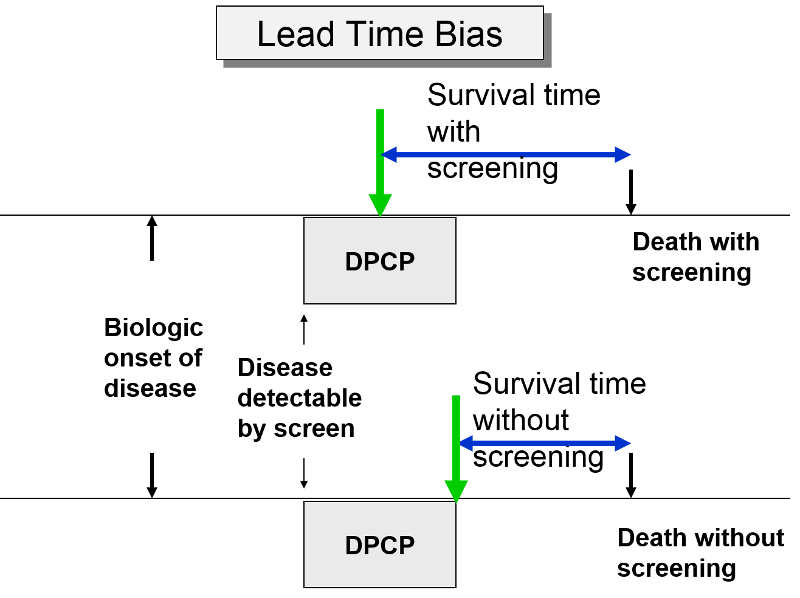
Lead-Time Bias
The premise of screening is that it allows you to identify disease earlier, so you can initiate treatment at an early stage in order to effect cure or at least longer survival. Screening can give you a jump on the disease; this "lead-time" is a good thing, but it can bias the efficacy of screening. The two subjects to the right have the same age, same time of disease onset, the same DPCP, and the same time of death. However, if we compare survival time from the point of diagnosis, the subject whose disease was identified through screening appears to survive longer, but only because their disease was identified earlier.
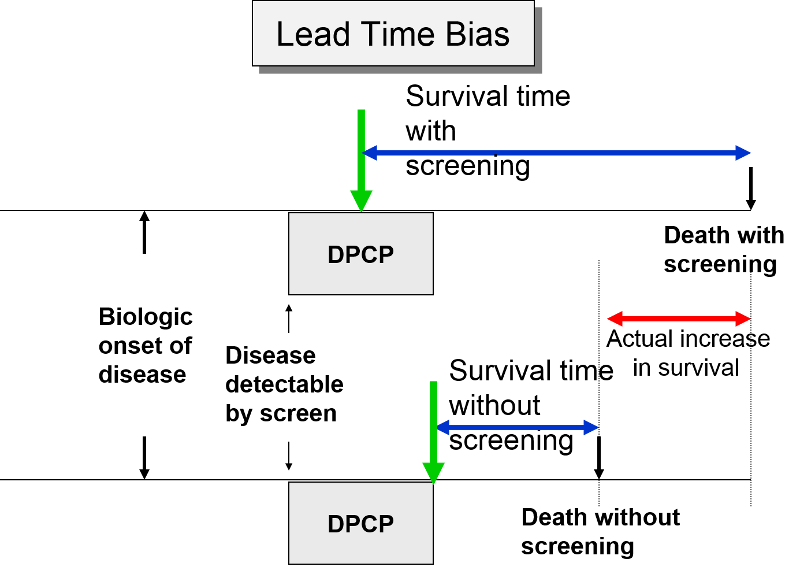
In the next figure two patients again have identical biologic onset and detectable pre-clinical phases. In this case the screened patient lives longer than the unscreened patient, but his survival time is still exaggerated by the lead time from earlier diagnosis.
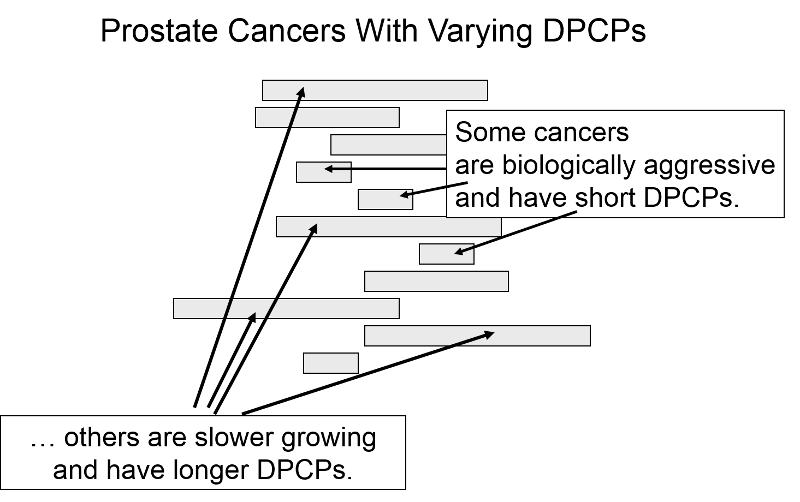
Length Time Bias
The length of the DPCP can vary substantially from person to person. Prostate cancer, for example, is a very slow growing tumor in many men, but very rapidly progressing and lethal in others. These differences in DPCP exaggerate the apparent benefit of screening, because there is a greater chance that screening will detect subjects with long DPCPs, and therefore, more benign disease.
To illustrate consider a hypothetical randomized trial in which half of the subjects were screened and the other half were not. Because we assigned subjects randomly, the DPCPs are more or less equally distributed in the two groups. If we conduct a screening in half of the subjects at a specific point in time, there is a greater probability that those who screen positive will have longer DPCPs on average, because they are detectable by screening, but their disease has not progressed to the stage of causing symptoms or death yet.
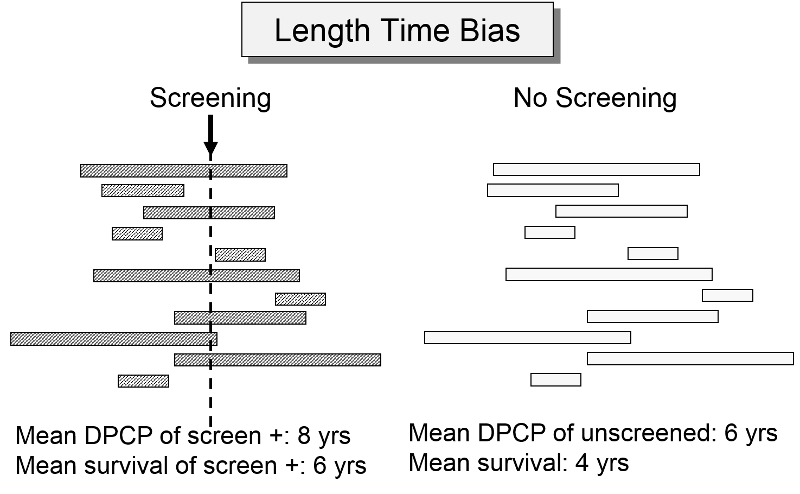
The unscreened population will include an assortment of subjects with long and short DPCPs, and they will all be identified by their symptoms and/or death. The screened subjects who are identified as having disease will tend to have longer survival times, because they have, on average, a less aggressive form of cancer.
For an nice summary of lead time bias, and length time bias follow this link: Primer on Lead-Time, Length, and Overdiagnosis Bias.