


Correlation
Correlation is one of the most common statistics. Using one single value, it describes the "degree of relationship" between two variables. Correlation ranges from -1 to +1. Negative values of correlation indicate that as one variable increases the other variable decreases. Positive values of correlation indicate that as one variable increase the other variable increases as well. There are three options to calculate correlation in R, and we will introduce two of them below.
For a nice synopsis of correlation, see https://statistics.laerd.com/statistical-guides/pearson-correlation-coefficient-statistical-guide.php
Pearson Correlation
The most commonly used type of correlation is Pearson correlation, named after Karl Pearson, introduced this statistic around the turn of the 20th century. Pearson's r measures the linear relationship between two variables, say X and Y. A correlation of 1 indicates the data points perfectly lie on a line for which Y increases as X increases. A value of -1 also implies the data points lie on a line; however, Y decreases as X increases. The formula for r is
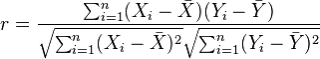
(in the same way that we distinguish between Ȳ and µ, similarly we distinguish r from ρ)
The Pearson correlation has two assumptions:
- The two variables are normally distributed. We can test this assumption using
- A statistical test (Shapiro-Wilk)
- A histogram
- A QQ plot
- The relationship between the two variables is linear. If this relationship is found to be curved, etc. we need to use another correlation test. We can test this assumption by examining the scatterplot between the two variables.
To calculate Pearson correlation, we can use the cor() function. The default method for cor() is the Pearson correlation. Getting a correlation is generally only half the story, and you may want to know if the relationship is statistically significantly different from 0.
- H0: There is no correlation between the two variables: ρ = 0
- Ha: There is a nonzero correlation between the two variables: ρ ≠ 0
To assess statistical significance, you can use cor.test() function.
> cor(fat$age, fat$pctfat.brozek, method="pearson")
[1] 0.2891735
> cor.test(fat$age, fat$pctfat.brozek, method="pearson")
Pearson's product-moment correlation
data: fat$age and fat$pctfat.brozek
t = 4.7763, df = 250, p-value = 3.045e-06
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
0.1717375 0.3985061
sample estimates:
cor
0.2891735
When testing the null hypothesis that there is no correlation between age and Brozek percent body fat, we reject the null hypothesis (r = 0.289, t = 4.77, with 250 degrees of freedom, and a p-value = 3.045e-06). As age increases so does Brozek percent body fat. The 95% confidence interval for the correlation between age and Brozek percent body fat is (0.17, 0.40). Note that this 95% confidence interval does not contain 0, which is consistent with our decision to reject the null hypothesis.
Spearman's rank correlation
Spearman's rank correlation is a nonparametric measure of the correlation that uses the rank of observations in its calculation, rather than the original numeric values. It measures the monotonic relationship between two variables X and Y. That is, if Y tends to increase as X increases, the Spearman correlation coefficient is positive. If Y tends to decrease as X increases, the Spearman correlation coefficient is negative. A value of zero indicates that there is no tendency for Y to either increase or decrease when X increases. The Spearman correlation measurement makes no assumptions about the distribution of the data.
The formula for Spearman's correlation ρs is
![]()
where di is the difference in the ranked observations from each group, (xi – yi), and n is the sample size. No need to memorize this formula!
> cor(fat$age,fat$pctfat.brozek, method="spearman")
[1] 0.2733830
> cor.test(fat$age,fat$pctfat.brozek, method="spearman")
Spearman's rank correlation rho
data: fat$age and fat$pctfat.brozek
S = 1937979, p-value = 1.071e-05
alternative hypothesis: true rho is not equal to 0
sample estimates:
rho
0.2733830
Thus we reject the null hypothesis that there is no (Spearman) correlation between age and Brozek percent fat (r = 0.27, p-value = 1.07e-05). As age increases so does percent body fat.
Some Notes on Correlation
Correlation, useful though it is, is one of the most misused statistics in all of science. People always seem to want a simple number describing a relationship. Yet data very, very rarely obey this imperative. It is clear what a Pearson correlation of 1 or -1 means, but how do we interpret a correlation of 0.4? It is not so clear.
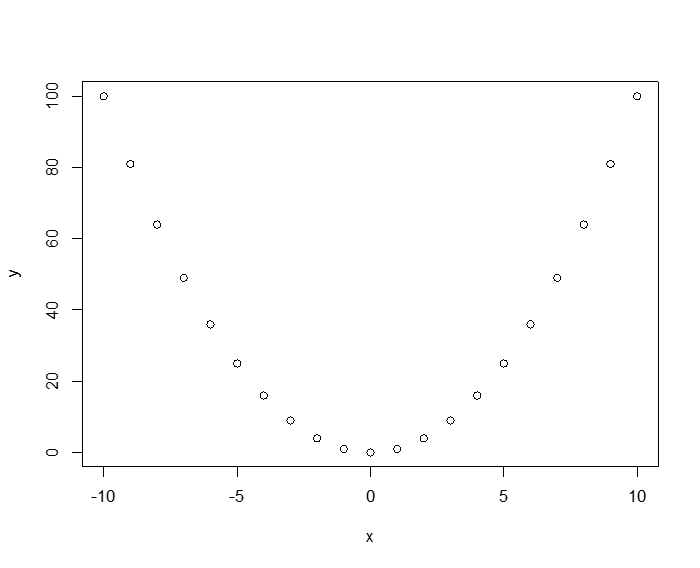
To see how the Pearson measure is dependent on the data distribution assumptions (in particular linearity), observe the following deterministic relationship: y = x2. Here the relationship between x and y isn't just "correlated," in the colloquial sense, it is totally deterministic! If we generate data for this relationship, the Pearson correlation is 0!
> x<-seq(-10,10, 1)
> y<-x*x
> plot(x,y)
> cor(x,y)
[1] 0
The third measure of correlation that the cor() command can take as argument is Kendall's Tau (T). Some people have argued that T is in some ways superior to the other two methods, but the fact remains, everyone still uses either Pearson or Spearman.
have argued that T is in some ways superior to the other two methods, but the fact remains, everyone still uses either Pearson or Spearman.
|
Conduct a comparison of Pearson correlation and Spearman correlation.
|

