


Descriptive Statistics for Continuous Variables
In order to provide a detailed description of the computations used for numerical and graphical summaries of continuous variables, we selected a small subset (n=10) of participants in the Framingham Heart Study. The data values for these ten participants are shown in the table below. The rightmost column contains the body mass index (BMI) computed using the height and weight measurements.
computed using the height and weight measurements.
Table 8 - Data Values for a Small Sample
|
Participant ID |
Systolic Blood Pressure |
Diastolic Blood Pressure |
Total Serum Cholesterol |
Weight |
Height |
Body Mass Index |
|---|---|---|---|---|---|---|
|
1 |
141 |
76 |
199 |
138 |
63.00 |
24.4 |
|
2 |
119 |
64 |
150 |
183 |
69.75 |
26.4 |
|
3 |
122 |
62 |
227 |
153 |
65.75 |
24.9 |
|
4 |
127 |
81 |
227 |
178 |
70.00 |
25.5 |
|
5 |
125 |
70 |
163 |
161 |
70.50 |
22.8 |
|
6 |
123 |
72 |
210 |
206 |
70.00 |
29.6 |
|
7 |
105 |
81 |
205 |
235 |
72.00 |
31.9 |
|
8 |
113 |
63 |
275 |
151 |
60.75 |
28.8 |
|
9 |
106 |
67 |
208 |
213 |
69.00 |
31.5 |
|
10 |
131 |
77 |
159 |
142 |
61.00 |
26.8 |
The first summary statistic that is important to report for a continuous variable (as well as for any discrete variable) is the sample size (in the example here, sample size is n=10). Larger sample sizes produce more precise results and therefore carry more weight. However, there is a point at which increasing the sample size will not materially increase the precision of the analysis. Sample size computations will be discussed in detail in a later module.
Because this sample is small (n=10), it is easy to summarize the sample by inspecting the observed values, for example, by listing the diastolic blood pressures in ascending order:
62 63 64 67 70 72 76 77 81 81
Diastolic blood pressures <80 mm Hg are considered normal, and we can see that the last two exceed the upper limit just barely. However, for a large sample, inspection of the individual data values does not provide a meaningful summary, and summary statistics are necessary. The two key components of a useful summary for a continuous variable are:
- a description of the center or 'average' of the data (i.e., what is a typical value?) and
- an indication of the variability in the data.
Sample Mean
In biostatistics, the term 'average' is a very general term that can be addressed by several statistics. The one that is most familiar is the sample mean, which is computed by summing all of the values and dividing by the sample size. For the sample of diastolic blood pressures in the table above, the sample mean is computed as follows:
Sample mean = (62+63+64+67+70+72+76+77+81+81) /10 = 71.3
To simplify the formulas for sample statistics (and for population parameters), we usually denote the variable of interest as "X". X is simply a placeholder for the variable being analyzed. Here X=diastolic blood pressure.
The general formula for the sample mean is:
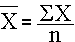
The X with the bar over it represents the sample mean, and it is read as "X bar". The Σ indicates summation (i.e., sum of the X's or sum of the diastolic blood pressures in this example).
When reporting summary statistics for a continuous variable, the convention is to report one more decimal place than the number of decimal places measured. Systolic and diastolic blood pressures, total serum cholesterol and weight were measured to the nearest integer, therefore the summary statistics are reported to the nearest tenth place. Height was measured to the nearest quarter inch (hundredths place), therefore the summary statistics are reported to the nearest thousandths place. Body mass index was computed to the nearest tenths place, summary statistics are reported to the nearest hundredths place.
Median
A second measure of the "average" value is the sample median, which is the middle value in the ordered data set, or the value that separates the top 50% of the values from the bottom 50%. When there is an odd number of observations in the sample, the median is the value that holds as many values above it as below it in the ordered data set. When there is an even number of observations in the sample (e.g., n=10) the median is defined as the mean of the two middle values in the ordered data set. In the sample of n=10 diastolic blood pressures, the two middle values are 70 and 72, and thus the median is (70+72)/2 = 71. Half of the diastolic blood pressures are above 71 and half are below. In this case, the sample mean and the sample median are very similar.
The mean and median provide different information about the average value of a continuous variable. Suppose the sample of 10 diastolic blood pressures looked like the following:
62 63 64 67 70 72 76 77 81 140
In this case, the sample mean (x 'bar') = 772/10 = 77.2, but this does not strike us as a "typical" value, since the majority of diastolic blood pressures in this sample are below 77.2. The extreme value of 140 is affecting the computation of the mean. For this same sample, the median is 71. The median is unaffected by extreme or outlying values. For this reason, the median is preferred over the mean when there are extreme values (either very small or very large values relative to the others). When there are no extreme values, the mean is the preferred measure of a typical value, in part because each observation is considered in the computation of the mean. When there are no extreme values in a sample, the mean and median of the sample will be close in value. Below we provide a more formal method to determine when values are extreme and thus when the median should be used.
Table 9 displays the sample means and medians for each of the continuous measures for the sample of n=10 in Table 8.
Table 9 - Means and Medians of Variables in Subsample of Size n=10
|
Variable |
Mean |
Median |
|---|---|---|
|
Diastolic Blood Pressure |
71.3 |
71 |
|
Systolic Blood Pressure |
121.2 |
122.5 |
|
Total Serum Cholesterol |
202.3 |
206.5 |
|
Weight |
176.0 |
169.5 |
|
Height |
67.175 |
69.375 |
|
Body Mass Index |
27.26 |
26.60 |
For each continuous variable measured in the subsample of n=10 participants, the means and medians are not identical but are relatively close in value suggesting that the mean is the most appropriate summary of a typical value for each of these variables. (If the mean and median are very different, it suggests that there are outliers affecting the mean.)
Mode
A third measure of a "typical" value for a continuous variable is the mode, which is defined as the most frequent value. In Table 8 above the mode of the diastolic blood pressures is 81, the mode of the total cholesterol levels is 227, the mode of the heights is 70.00, because these values each appear twice when the other values only appear only once. For each of the other continuous variables, there are 10 distinct values and thus there is no mode, since no value appears more frequently than any other.
Suppose the diastolic blood pressures had been:
62 63 64 64 70 72 76 77 81 81
In this sample there are two modes: 64 and 81. The mode is a useful summary statistic for a continuous variable. It is not presented instead of either the mean or the median, but rather in addition to the mean or median.
Range
The second aspect of a continuous variable that must be summarized is the variability in the sample. A relatively crude, yet important, measure of variability in a sample is the sample range. The sample range is computed as follows:
Sample Range = Maximum – Minimum Value
Table 10 displays the sample ranges for each of the continuous measures in the subsample of n=10 observations.
Table 10 Ranges of Variables in Subsample of Size n=10
|
Variable |
Minimum |
Maximum |
Range |
|---|---|---|---|
|
Diastolic Blood Pressure |
62 |
81 |
19 |
|
Systolic Blood Pressure |
105 |
141 |
36 |
|
Total Serum Cholesterol |
150 |
275 |
125 |
|
Weight |
138 |
235 |
97 |
|
Height |
60.75 |
72.00 |
11.25 |
|
Body Mass Index |
22.8 |
31.9 |
9.1 |
The range of a variable depends on the scale of measurement. The blood pressures are measured in millimeters of mercury; total cholesterol is measured in milligrams per deciliter, weight in pounds, and so on. The range of total serum cholesterol is large with the minimum and maximum in the sample of size n=10 differing by 125 units. In contrast, the heights of participants are more homogeneous with a range of 11.25 inches. The range is an important descriptive statistic for a continuous variable, but it is based only on two values in the data set. Like the mean, the sample range can be affected by extreme values and thus it must be interpreted with caution. The most widely used measure of variability for a continuous variable is called the standard deviation, which is illustrated below.