


Nucleic Acids
There are two types of nucleic acids that are important to living things.
- DNA (deoxyribonucleic acid)
- RNA (ribonucleic acid)
These molecules are also polymers of smaller units called nucleotides; each nucleotide consist of a sugar (ribose or deoxyribose), a phosphate group, and one of several "bases" that are either purines or pyrimidines. Alternating sugar molecules and phosphate groups are bonded together to form the backbone of the nucleic acid, and a purine or pyrimidine base is bonded to each of the sugars, as illustrated below.
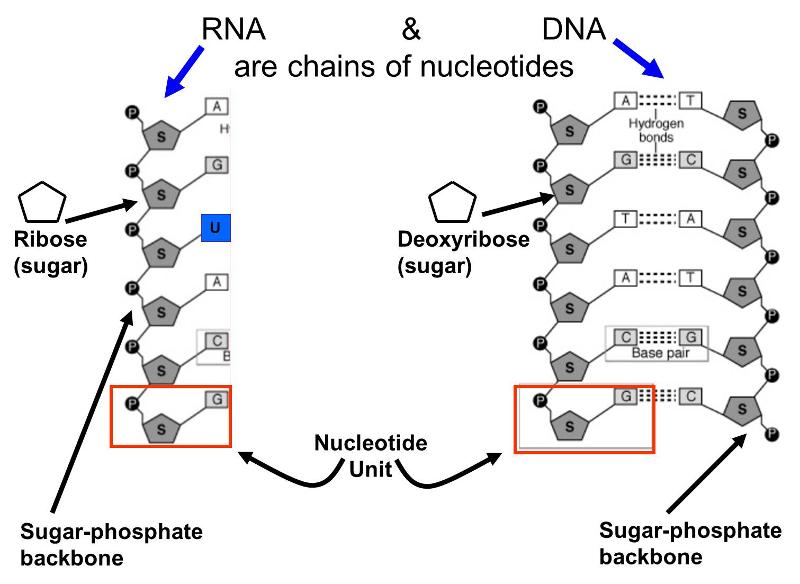
There are several differences between DNA and RNA.
- DNA contains the sugar deoxyribose, while RNA contains the sugar ribose.
- DNA consists of two nucleotide chains that are bonded to together by weak hydrogen bonds between complementary base pairs. The double strands are wrapped to form a double helix.
- The bases found in DNA are limited to adenine, cytosine, guanine, and thymine; RNA has adenine, cytosine, and guanine, but hase another base called uracil instead of thymine.
The cells of living organisms have chromosomes which contain an inherited code for synthesizing all of the proteins that the organism produces. In essence, each chromosome is a gigantic molecule of double stranded DNA wound tightly into a double helix. A single chromosome contains thousands of genes, segments of DNA that encode for specific proteins. In a highly regulated process, cellular enzymes can unwind a particular segment (gene), and other enzymes move along a gene using one strand of DNA as a template to synthesize a complementary strand of messenger RNA. This newly synthesized messenger RNA will then leave the cell nucleus and move to the cytoplasm of the cell where the RNA will in turn be used as a template to synthesize a specific protein.
This process will be clearer when we explore it in more detail in another online module. For the time being the video below provides an overview of this process that will be helpful.
An Overview of Transcription and Translation
This short animation from the Discovery Channel provides a nice overview of the transcription and translation. Transcription is the process by which a gene, segment of DNA that encodes for a specific protein, serves as a template for the synthesis of a messenger RNA (mRNA) for that specific protein. Transcription takes place inside the cell nucleus where chromosomal DNA is located. The mRNA then leaves the nucleus through special pores in the membrane of the nucleus. Once the mRNA emerges from the nucleus, it attaches to a two part structure called a ribosome, which consists of ribosomal RNA (rRNA). Enzymes also attach to the ribosomal complex and aid in the process of translation, in which the coded sequence of bases on the mRNA is translated and directs the synthesis of a chain of amino acids, which are the building blocks of proteins.
![]()
![]()
Source: http://youtu.be/1fiJupfbSpg
Proteins
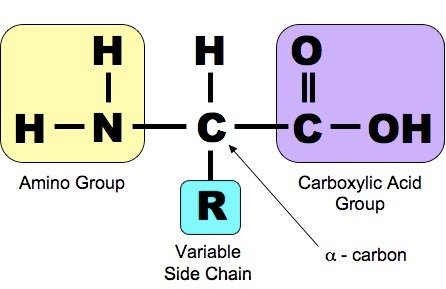
Proteins are another class of enormously diverse organic molecules that are made from multiple units of simpler molecules arranged in chains. All proteins are made from combinations of the 20 amino acids show below. As shown below, each of these 20 amino acids has a central carbon (the alpha carbon) bonded to an amino group (-NH2 i.e., nitrogen bonded to two hydrogens) at one end and a carboxyl group ( -COOH) at the other end.
Source: http://study.com/academy/lesson/threonine-amino-acid-structure-function.html
What distinguishes one amino acid from another is the side chain of atoms that is also bonded to the alpha carbon (designated "R-group on the right).
.gif)
Source: http://quotesgram.com/amino-quotes/
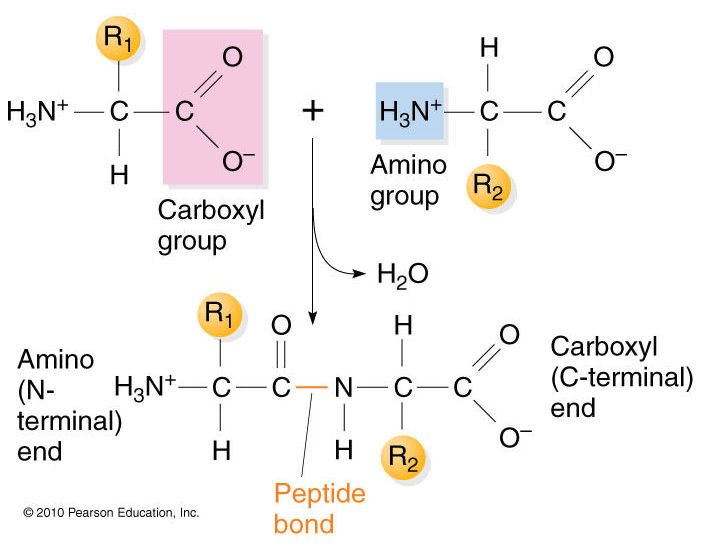
The primary structure of proteins results from linking together various combinations of these 20 amino acids with peptide bonds, which link the carboxyl group of one amino acid to the amino group of another amino acid.
results from linking together various combinations of these 20 amino acids with peptide bonds, which link the carboxyl group of one amino acid to the amino group of another amino acid.
Source: https://biochemistry3rst.wordpress.com/tag/proteins/
Now imagine that dozens or even hundreds of amino acides are linked together in chains of varying length to create the primary structure of a protein. Proteins are sometimes referred to as polypeptides because they consist of chains of amino acids linked together with peptide bonds.
Secondary Structure of Proteins
The chains of amino acids establish the primary structure of a protein, but interactions (both attractive forces and repulsive forces) among the components of the chain reshape the protein into its filnal three-dimensional structure. These attractive and repulsive forces among the amino acids in the chain cause segments of the chain to take on one of several characteristic forms that provide the secondary structure of the protein. For example, the hydrogen on the amino group of one amino acid can form a weak "hydrogen bond" to the oxygen atom in the carboxyl group of another amino acid elsewhere on the chain. Hydrogen bonding can cause portions of the polypeptide chain to form zig-zag sections called "beta sheets" (which are very prominent in the protein fiber in silk, for example), and it can also cause sections of the polypeptide to twist into a cork screw-shaped structure called an "alpha helix." Other sections of a polypeptide may be referred to as "random coils" because they fold but do not have a regular structural shape.
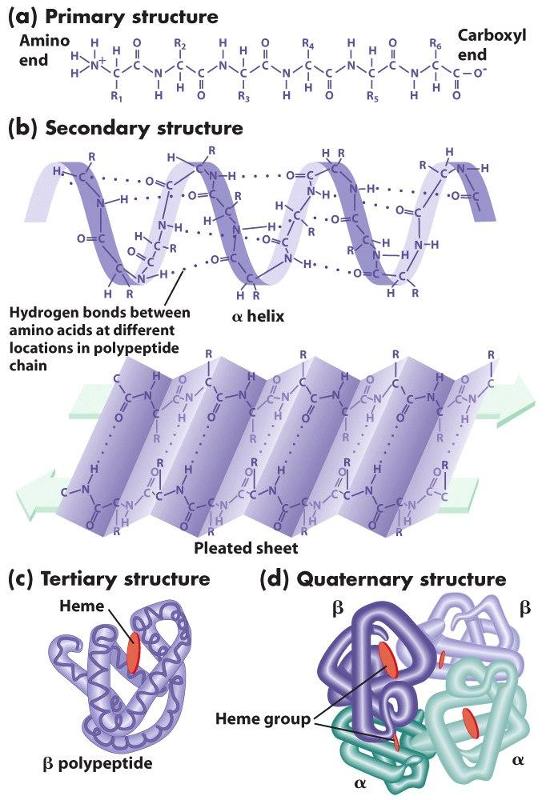
Proteins also have a tertiary level of structure as a result of ionic, hydrogen, or covalent bonds between the "-R" groups of the amino acids. As a result, alpha helical segments, beta pleated sheets, and random coils fold upon themselves. Folding and placement in a cell will also be influenced by the polarity of the amino acids. Some amino acids have side chains that are polar and others have non-polar side chains. If some sections of the chain contain mostly non-polar amino acids, while other sections contain mostly polar amino acids, the non-polar sections will self-associate in the interior of the molecule away from water, and the polar sections will be arrayed on the exterior of the molecule.
Finally, quaternary structure refers to the association of two or more polypeptide chains or subunits into a larger entity. For example, the hemoglobin molecule (shown in (d) to the left) consists of two alpha subunits and two beta subunits; each of these four polypeptide chains has a binding site for oxygen. Transport proteins in cell membranes frequently consist of multiple subunits as well.
The three dimensional structure of proteins goes hand in hand with their function. Moreover, the three dimensional shape of a protein (its conformation) may change depending on changes in its local environment, and this also may relate to its function. To illustrate, consider the function of an enzyme whose purpose is to cleave the phosphate groups from a molecule called cyclic AMP. The enzyme is depicted in the figure to the right. The drawings on the left side of the figure show the enzyme folding into its quaternary conformation (folded protein), and the drawing on the right is a close up of the binding site, showing a molecule of cyclic AMP (pink shading) nestled in the arms of the binding site. Chemical groups on the cyclic AMP (the substrate) are interacting with chemical groups on the enzyme through ionic and hydrogen bonds. The binding site is specific for cyclic AMP, which fits into the protein binding site in much the same way that a key fits into a specific lock. This interaction then causes the conformation of the enzyme to change, and this bends the cyclic AMP in a way that facilitates cleavage of the phosphate group. Once this occurs, the two resulting products are released, and the enzyme reverts back to its resting conformation.
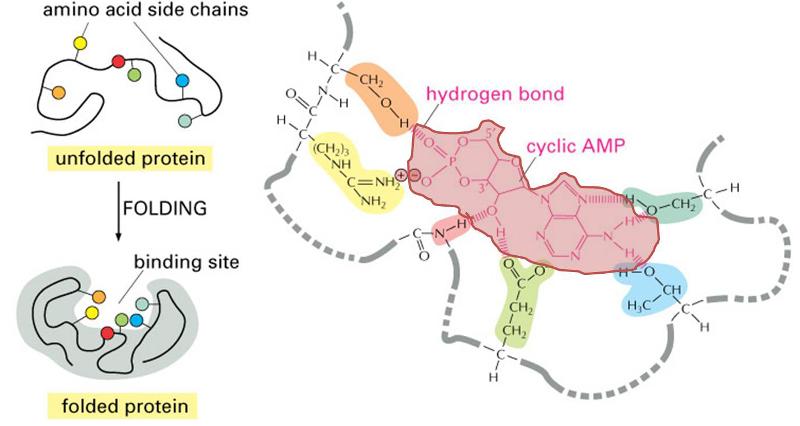
(Illustration adapted from http://accessexcellence.org/RC/VL/GG/ecb/protein_binding_site.php )
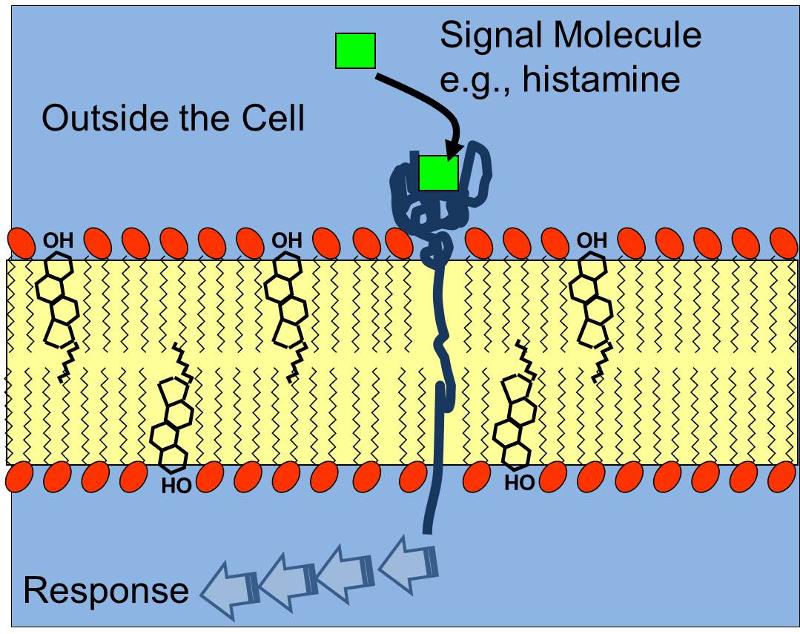
The three dimensional shape of proteins and this concept of a specific binding site is relevant not only for the interaction of enzymes and their substrates, but also for receptors which bind chemical signals in a specific way, e.g,, a protein receptor embeded in the cell membrane that has a complementary shape to the signal molecule histamine receptor as illustrated below. Binding of histamine molecules to their corresponding receptors causes a change in the conformation of the proein receptor that triggers a series of biochemical responses within the cell, such as contraction of smooth muscle cells in thr bronchi of a child having an asthma attack.
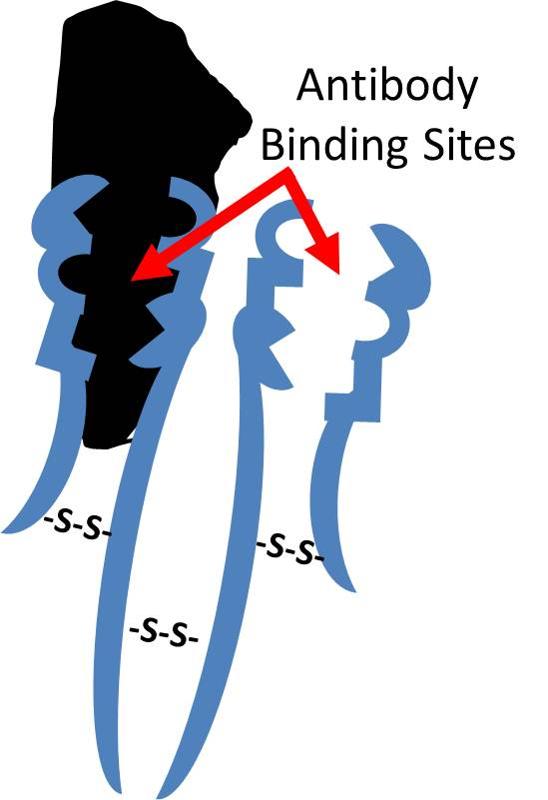
Antibodies that are produced in response to infections have binding sites that enable them to bind to complementary shapes on foreign proteins. The illustration below shows an IgG antibody in blue, composed of two short polypeptide chains and two long chains that are held together with disulfide bonds (S-S).The two identical binding sites on this antibody have binding pockets that enable them to bind in a highly specific way to complementary shapes on foreign molecules (shown in black). Binding to foreigh substances can neutralize them and also tag them to facilitate their removal by white blood cells.
As final example, consider the hormone insulin, which binds to specific pockets on insulin receptors embeded in the cell membranes of fat cells and muscle cells. Once again, binding causes a change in the conformation (shape) of the receptor protein which triggers a sequence of biochemical events that result in the insertion of glucose transporters (transmembrane transport proteins) into the plasma membrane as shown below.
As you will see in the next section, the structure of proteins enables them to serve a wide variety of functions.