

Cox Proportional Hazards Regression Analysis
Survival analysis methods can also be extended to assess several risk factors simultaneously similar to multiple linear and multiple logistic regression analysis as described in the modules discussing Confounding, Effect Modification, Correlation, and Multivariable Methods. One of the most popular regression techniques for survival analysis is Cox proportional hazards regression, which is used to relate several risk factors or exposures, considered simultaneously, to survival time. In a Cox proportional hazards regression model, the measure of effect is the hazard rate, which is the risk of failure (i.e., the risk or probability of suffering the event of interest), given that the participant has survived up to a specific time. A probability must lie in the range 0 to 1. However, the hazard represents the expected number of events per one unit of time. As a result, the hazard in a group can exceed 1. For example, if the hazard is 0.2 at time t and the time units are months, then on average, 0.2 events are expected per person at risk per month. Another interpretation is based on the reciprocal of the hazard. For example, 1/0.2 = 5, which is the expected event-free time (5 months) per person at risk.
In most situations, we are interested in comparing groups with respect to their hazards, and we use a hazard ratio, which is analogous to an odds ratio in the setting of multiple logistic regression analysis. The hazard ratio can be estimated from the data we organize to conduct the log rank test. Specifically, the hazard ratio is the ratio of the total number of observed to expected events in two independent comparison groups:

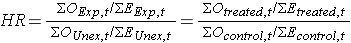
In some studies, the distinction between the exposed or treated as compared to the unexposed or control groups are clear. In other studies, it is not. In the latter case, either group can appear in the numerator and the interpretation of the hazard ratio is then the risk of event in the group in the numerator as compared to the risk of event in the group in the denominator.
In Example 3 there are two active treatments being compared (chemotherapy before surgery versus chemotherapy after surgery). Consequently, it does not matter which appears in the numerator of the hazard ratio. Using the data in Example 3, the hazard ratio is estimated as:
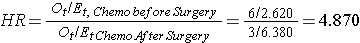
Thus, the risk of death is 4.870 times higher in the chemotherapy before surgery group as compared to the chemotherapy after surgery group.
Example 3 examined the association of a single independent variable (chemotherapy before or after surgery) on survival. However, it is often of interest to assess the association between several risk factors, considered simultaneously, and survival time. One of the most popular regression techniques for survival outcomes is Cox proportional hazards regression analysis. There are several important assumptions for appropriate use of the Cox proportional hazards regression model, including
- independence of survival times between distinct individuals in the sample,
- a multiplicative relationship between the predictors and the hazard (as opposed to a linear one as was the case with multiple linear regression analysis, discussed in more detail below), and
- a constant hazard ratio over time.
The Cox proportional hazards regression model can be written as follows:
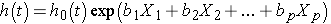
where h(t) is the expected hazard at time t, h0(t) is the baseline hazard and represents the hazard when all of the predictors (or independent variables) X1, X2 , Xp are equal to zero. Notice that the predicted hazard (i.e., h(t)), or the rate of suffering the event of interest in the next instant, is the product of the baseline hazard (h0(t)) and the exponential function of the linear combination of the predictors. Thus, the predictors have a multiplicative or proportional effect on the predicted hazard.
Consider a simple model with one predictor, X1. The Cox proportional hazards model is:
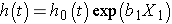
Suppose we wish to compare two participants in terms of their expected hazards, and the first has X1= a and the second has X1= b. The expected hazards are h(t) = h0(t)exp (b1a) and h(t) = h0(t)exp (b1b), respectively.
The hazard ratio is the ratio of these two expected hazards: h0(t)exp (b1a)/ h0(t)exp (b1b) = exp(b1(a-b)) which does not depend on time, t. Thus the hazard is proportional over time.
Sometimes the model is expressed differently, relating the relative hazard, which is the ratio of the hazard at time t to the baseline hazard, to the risk factors:
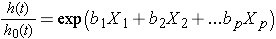
We can take the natural logarithm (ln) of each side of the Cox proportional hazards regression model, to produce the following which relates the log of the relative hazard to a linear function of the predictors. Notice that the right hand side of the equation looks like the more familiar linear combination of the predictors or risk factors (as seen in the multiple linear regression model).
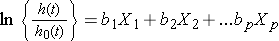
In practice, interest lies in the associations between each of the risk factors or predictors (X1, X2, ..., Xp) and the outcome. The associations are quantified by the regression coefficients coefficients (b1, b2, ..., bp). The technique for estimating the regression coefficients in a Cox proportional hazards regression model is beyond the scope of this text and is described in Cox and Oakes.9 Here we focus on interpretation. The estimated coefficients in the Cox proportional hazards regression model, b1, for example, represent the change in the expected log of the hazard ratio relative to a one unit change in X1, holding all other predictors constant.
The antilog of an estimated regression coefficient, exp(bi), produces a hazard ratio. If a predictor is dichotomous (e.g., X1 is an indicator of prevalent cardiovascular disease or male sex) then exp(b1) is the hazard ratio comparing the risk of event for participants with X1=1 (e.g., prevalent cardiovascular disease or male sex) to participants with X1=0 (e.g., free of cardiovascular disease or female sex).
If the hazard ratio for a predictor is close to 1 then that predictor does not affect survival. If the hazard ratio is less than 1, then the predictor is protective (i.e., associated with improved survival) and if the hazard ratio is greater than 1, then the predictor is associated with increased risk (or decreased survival).
Tests of hypothesis are used to assess whether there are statistically significant associations between predictors and time to event. The examples that follow illustrate these tests and their interpretation.
The Cox proportional hazards model is called a semi-parametric model, because there are no assumptions about the shape of the baseline hazard function. There are however, other assumptions as noted above (i.e., independence, changes in predictors produce proportional changes in the hazard regardless of time, and a linear association between the natural logarithm of the relative hazard and the predictors). There are other regression models used in survival analysis that assume specific distributions for the survival times such as the exponential, Weibull, Gompertz and log-normal distributions1,8. The exponential regression survival model, for example, assumes that the hazard function is constant. Other distributions assume that the hazard is increasing over time, decreasing over time, or increasing initially and then decreasing. Example 5 will illustrate estimation of a Cox proportional hazards regression model and discuss the interpretation of the regression coefficients.
Example:
An analysis is conducted to investigate differences in all-cause mortality between men and women participating in the Framingham Heart Study adjusting for age. A total of 5,180 participants aged 45 years and older are followed until time of death or up to 10 years, whichever comes first. Forty six percent of the sample are male, the mean age of the sample is 56.8 years (standard deviation = 8.0 years) and the ages range from 45 to 82 years at the start of the study. There are a total of 402 deaths observed among 5,180 participants. Descriptive statistics are shown below on the age and sex of participants at the start of the study classified by whether they die or do not die during the follow up period.
|
|
Die (n=402) |
Do Not Die (n=4778) |
|---|---|---|
|
Mean (SD) Age, years |
65.6 (8.7) |
56.1 (7.5) |
|
N (%) Male |
221 (55%) |
2145 (45%) |
We now estimate a Cox proportional hazards regression model and relate an indicator of male sex and age, in years, to time to death. The parameter estimates are generated in SAS using the SAS Cox proportional hazards regression procedure12 and are shown below along with their p-values.
|
Risk Factor |
Parameter Estimate |
P-Value |
|---|---|---|
|
Age, years |
0.11149 |
0.0001 |
|
Male Sex |
0.67958 |
0.0001 |
Note that there is a positive association between age and all-cause mortality and between male sex and all-cause mortality (i.e., there is increased risk of death for older participants and for men).
Again, the parameter estimates represent the increase in the expected log of the relative hazard for each one unit increase in the predictor, holding other predictors constant. There is a 0.11149 unit increase in the expected log of the relative hazard for each one year increase in age, holding sex constant, and a 0.67958 unit increase in expected log of the relative hazard for men as compared to women, holding age constant.
For interpretability, we compute hazard ratios by exponentiating the parameter estimates. For age, exp(0.11149) = 1.118. There is an 11.8% increase in the expected hazard relative to a one year increase in age (or the expected hazard is 1.12 times higher in a person who is one year older than another), holding sex constant. Similarly, exp(0.67958) = 1.973. The expected hazard is 1.973 times higher in men as compared to women, holding age constant.
Suppose we consider additional risk factors for all-cause mortality and estimate a Cox proportional hazards regression model relating an expanded set of risk factors to time to death. The parameter estimates are again generated in SAS using the SAS Cox proportional hazards regression procedure and are shown below along with their p-values.12 Also included below are the hazard ratios along with their 95% confidence intervals.
|
Risk Factor |
Parameter Estimate |
P-Value |
Hazard Ratio (HR) (95% CI for HR) |
|---|---|---|---|
|
Age, years |
0.11691 |
0.0001 |
1.124 (1.111-1.138) |
|
Male Sex |
0.40359 |
0.0002 |
1.497 (1.215-1.845) |
|
Systolic Blood Pressure |
0.01645 |
0.0001 |
1.017 (1.012-1.021) |
|
Current Smoker |
0.76798 |
0.0001 |
2.155 (1.758-2.643) |
|
Total Serum Cholesterol |
-0.00209 |
0.0963 |
0.998 (0.995-2.643) |
|
Diabetes |
-0.02366 |
0.1585 |
0.816 (0.615-1.083) |
All of the parameter estimates are estimated taking the other predictors into account. After accounting for age, sex, blood pressure and smoking status, there are no statistically significant associations between total serum cholesterol and all-cause mortality or between diabetes and all-cause mortality. This is not to say that these risk factors are not associated with all-cause mortality; their lack of significance is likely due to confounding (interrelationships among the risk factors considered). Notice that for the statistically significant risk factors (i.e., age, sex, systolic blood pressure and current smoking status), that the 95% confidence intervals for the hazard ratios do not include 1 (the null value). In contrast, the 95% confidence intervals for the non-significant risk factors (total serum cholesterol and diabetes) include the null value.
Example:
A prospective cohort study is run to assess the association between body mass index and time to incident cardiovascular disease (CVD). At baseline, participants' body mass index is measured along with other known clinical risk factors for cardiovascular disease (e.g., age, sex, blood pressure). Participants are followed for up to 10 years for the development of CVD. In the study of n=3,937 participants, 543 develop CVD during the study observation period. In a Cox proportional hazards regression analysis, we find the association between BMI and time to CVD statistically significant with a parameter estimate of 0.02312 (p=0.0175) relative to a one unit change in BMI.
If we exponentiate the parameter estimate, we have a hazard ratio of 1.023 with a confidence interval of (1.004-1.043). Because we model BMI as a continuous predictor, the interpretation of the hazard ratio for CVD is relative to a one unit change in BMI (recall BMI is measured as the ratio of weight in kilograms to height in meters squared). A one unit increase in BMI is associated with a 2.3% increase in the expected hazard.
To facilitate interpretation, suppose we create 3 categories of weight defined by participant's BMI.
- Normal weight is defined as BMI < 25.0,
- Overweight as BMI between 25.0 and 29.9, and
- Obese as BMI exceeding 29.9.
In the sample, there are 1,651 (42%) participants who meet the definition of normal weight, 1,648 (42%) who meet the definition of over weight, and 638 (16%) who meet the definition of obese. The numbers of CVD events in each of the 3 groups are shown below.
|
Group |
Number of Participants |
Number (%) of CVD Events |
|---|---|---|
|
Normal Weight |
1651 |
202 (12.2%) |
|
Overweight |
1648 |
241 (14.6%) |
|
Obese |
638 |
100 (15.7%) |
The incidence of CVD is higher in participants classified as overweight and obese as compared to participants of normal weight.
We now use Cox proportional hazards regression analysis to make maximum use of the data on all participants in the study. The following table displays the parameter estimates, p-values, hazard ratios and 95% confidence intervals for the hazards ratios when we consider the weight groups alone (unadjusted model), when we adjust for age and sex and when we adjust for age, sex and other known clinical risk factors for incident CVD.
The latter two models are multivariable models and are performed to assess the association between weight and incident CVD adjusting for confounders. Because we have three weight groups, we need two dummy variables or indicator variables to represent the three groups. In the models we include the indicators for overweight and obese and consider normal weight the reference group.
|
|
Overweight |
Obese |
||||
|---|---|---|---|---|---|---|
|
Model |
Parameter Estimate |
P- Value |
HR (95% CI for HR) |
Parameter Estimate |
P- Value |
HR (95% CI for HR) |
|
Unadjusted or Crude Model |
0.19484 |
0.0411 |
1.215 (1.008-1.465) |
0.27030 |
0.0271 |
1.310 (1.031-1.665) |
|
Age and Sex Adjusted |
0.06525 |
0.5038 |
1.067 (0.882-1.292) |
0.28960 |
0.0188 |
1.336 (1.049-1.701) |
|
Adjusted for Clinical Risk Factors* |
0.07503 |
0.4446 |
1.078 (0.889-1.307) |
0.24944 |
0.0485 |
1.283 (1.002-1.644) |
* Adjusted for age, sex, systolic blood pressure, treatment for hypertension, current smoking status, total serum cholesterol.
In the unadjusted model, there is an increased risk of CVD in overweight participants as compared to normal weight and in obese as compared to normal weight participants (hazard ratios of 1.215 and 1.310, respectively). However, after adjustment for age and sex, there is no statistically significant difference between overweight and normal weight participants in terms of CVD risk (hazard ratio = 1.067, p=0.5038). The same is true in the model adjusting for age, sex and the clinical risk factors. However, after adjustment, the difference in CVD risk between obese and normal weight participants remains statistically significant, with approximately a 30% increase in risk of CVD among obese participants as compared to participants of normal weight.