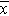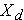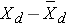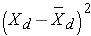Confidence Intervals
Author:
Lisa Sullivan, PhD
Professor of Biostatistics
Boston University School of Public Health
As noted in earlier modules a key goal in applied biostatistics is to make inferences about unknown population parameters based on sample statistics. There are two broad areas of statistical inference, estimation and hypothesis testing. Estimation is the process of determining a likely value for a population parameter (e.g., the true population mean or population proportion) based on a random sample. In practice, we select a sample from the target population and use sample statistics (e.g., the sample mean or sample proportion) as estimates of the unknown parameter. The sample should be representative of the population, with participants selected at random from the population. In generating estimates, it is also important to quantify the precision of estimates from different samples.
After completing this module, the student will be able to:

There are a number of population parameters of potential interest when one is estimating health outcomes (or "endpoints"). Many of the outcomes we are interested in estimating are either continuous or dichotomous variables, although there are other types which are discussed in a later module. The parameters to be estimated depend not only on whether the endpoint is continuous or dichotomous, but also on the number of groups being studied. Moreover, when two groups are being compared, it is important to establish whether the groups are independent (e.g., men versus women) or dependent (i.e., matched or paired, such as a before and after comparison). The table below summarizes parameters that may be important to estimate in health-related studies.
|
|
Parameters Being Estimated |
|
|---|---|---|
|
|
Continuous Variable |
Dichotomous Variable |
|
One Sample |
mean |
proportion or rate, e.g., prevalence, cumulative incidence, incidence rate |
|
Two Independent Samples |
difference in means |
difference in proportions or rates, e.g., risk difference, rate difference, risk ratio, odds ratio, attributable proportion |
|
Two Dependent, Matched Samples |
mean difference |
|
There are two types of estimates for each population parameter: the point estimate and confidence interval (CI) estimate. For both continuous variables (e.g., population mean) and dichotomous variables (e.g., population proportion) one first computes the point estimate from a sample. Recall that sample means and sample proportions are unbiased estimates of the corresponding population parameters.
For both continuous and dichotomous variables, the confidence interval estimate (CI) is a range of likely values for the population parameter based on:
Strictly speaking a 95% confidence interval means that if we were to take 100 different samples and compute a 95% confidence interval for each sample, then approximately 95 of the 100 confidence intervals will contain the true mean value (μ). In practice, however, we select one random sample and generate one confidence interval, which may or may not contain the true mean. The observed interval may over- or underestimate μ. Consequently, the 95% CI is the likely range of the true, unknown parameter. The confidence interval does not reflect the variability in the unknown parameter. Rather, it reflects the amount of random error in the sample and provides a range of values that are likely to include the unknown parameter. Another way of thinking about a confidence interval is that it is the range of likely values of the parameter (defined as the point estimate + margin of error) with a specified level of confidence (which is similar to a probability).
Suppose we want to generate a 95% confidence interval estimate for an unknown population mean. This means that there is a 95% probability that the confidence interval will contain the true population mean. Thus, P( [sample mean] - margin of error < μ < [sample mean] + margin of error) = 0.95.
The Central Limit Theorem introduced in the module on Probability stated that, for large samples, the distribution of the sample means is approximately normally distributed with a mean:
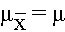
and a standard deviation (also called the standard error):
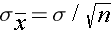
For the standard normal distribution, P(-1.96 < Z < 1.96) = 0.95, i.e., there is a 95% probability that a standard normal variable, Z, will fall between -1.96 and 1.96. The Central Limit Theorem states that for large samples:
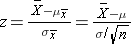
By substituting the expression on the right side of the equation:
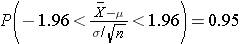
Using algebra, we can rework this inequality such that the mean (μ) is the middle term, as shown below.
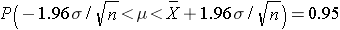
then
and finally
This last expression, then, provides the 95% confidence interval for the population mean, and this can also be expressed as:
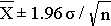
Thus, the margin of error is 1.96 times the standard error (the standard deviation of the point estimate from the sample), and 1.96 reflects the fact that a 95% confidence level was selected. So, the general form of a confidence interval is:
point estimate + Z SE (point estimate)
where Z is the value from the standard normal distribution for the selected confidence level (e.g., for a 95% confidence level, Z=1.96).
In practice, we often do not know the value of the population standard deviation (σ). However, if the sample size is large (n > 30), then the sample standard deviations can be used to estimate the population standard deviation.
Table - Z-Scores for Commonly Used Confidence Intervals
|
Desired Confidence Interval |
Z Score |
|
90% 95% 99% |
1.645 1.96 2.576 |

In the health-related publications a 95% confidence interval is most often used, but this is an arbitrary value, and other confidence levels can be selected. Note that for a given sample, the 99% confidence interval would be wider than the 95% confidence interval, because it allows one to be more confident that the unknown population parameter is contained within the interval.
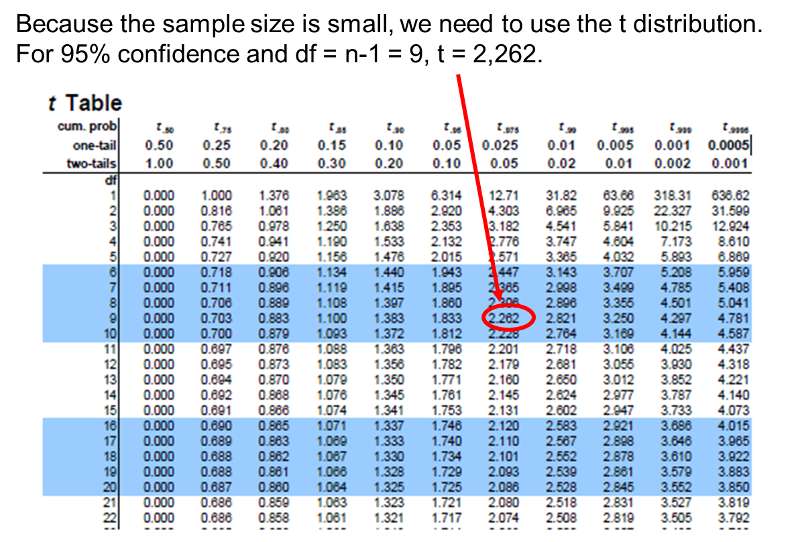
With smaller samples (n< 30) the Central Limit Theorem does not apply, and another distribution called the t distribution must be used. The t distribution is similar to the standard normal distribution but takes a slightly different shape depending on the sample size. In a sense, one could think of the t distribution as a family of distributions for smaller samples. Instead of "Z" values, there are "t" values for confidence intervals which are larger for smaller samples, producing larger margins of error, because small samples are less precise. t values are listed by degrees of freedom (df). Just as with large samples, the t distribution assumes that the outcome of interest is approximately normally distributed.
A table of t values is shown in the frame below. Note that the table can also be accessed from the "Other Resources" on the right side of the page.
Suppose we wish to estimate the mean systolic blood pressure, body mass index, total cholesterol level or white blood cell count in a single target population. We select a sample and compute descriptive statistics including the sample size (n), the sample mean, and the sample standard deviation (s). The formulas for confidence intervals for the population mean depend on the sample size and are given below.
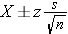
Use the Z table for the standard normal distribution.
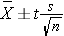
Use the t table with df=n-1
Example: Descriptive statistics on variables measured in a sample of a n=3,539 participants attending the 7th examination of the offspring in the Framingham Heart Study are shown below.
|
Characteristic |
n |
Sample Mean |
Standard Deviation (s) |
|
Systolic Blood Pressure |
3,534 |
127.3 |
19.0 |
|
Diastolic Blood Pressure |
3,532 |
74.0 |
9.9 |
|
Total Serum Cholesterol |
3,310 |
200.3 |
36.8 |
|
Weight |
3,506 |
174.4 |
38.7 |
|
Height |
3,326 |
65.957 |
3.749 |
|
Body Mass Index |
3,326 |
28.15 |
5.32 |
Because the sample is large, we can generate a 95% confidence interval for systolic blood pressure using the following formula:
The Z value for 95% confidence is Z=1.96. [Note: Both the table of Z-scores and the table of t-scores can also be accessed from the "Other Resources" on the right side of the page.]
Substituting the sample statistics and the Z value for 95% confidence, we have
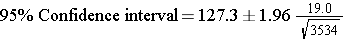
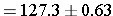
So the confidence interval is
(126.7,127.9)
A point estimate for the true mean systolic blood pressure in the population is 127.3, and we are 95% confident that the true mean is between 126.7 and 127.9. The margin of error is very small here because of the large sample size

What is the 90% confidence interval for BMI? (Note that Z=1.645 to reflect the 90% confidence level.)
Answer
The table below shows data on a subsample of n=10 participants in the 7th examination of the Framingham Offspring Study.
|
Characteristic |
n |
Sample Mean |
Standard Deviation (s) |
|
Systolic Blood Pressure |
10 |
121.2 |
11.1 |
|
Diastolic Blood Pressure |
10 |
71.3 |
7.2 |
|
Total Serum Cholesterol |
10 |
202.3 |
37.7 |
|
Weight |
10 |
176.0 |
33.0 |
|
Height |
10 |
67.175 |
4.205 |
|
Body Mass Index |
10 |
27.26 |
3.10 |
Suppose we compute a 95% confidence interval for the true systolic blood pressure using data in the subsample. Because the sample size is small, we must now use the confidence interval formula that involves t rather than Z.
The sample size is n=10, the degrees of freedom (df) = n-1 = 9. The t value for 95% confidence with df = 9 is t = 2.262.
Substituting the sample statistics and the t value for 95% confidence, we have the following expression:
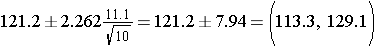 .
.
Interpretation: Based on this sample of size n=10, our best estimate of the true mean systolic blood pressure in the population is 121.2. Based on this sample, we are 95% confident that the true systolic blood pressure in the population is between 113.3 and 129.1. Note that the margin of error is larger here primarily due to the small sample size.
Using the subsample in the table above, what is the 90% confidence interval for BMI?
Answer
Suppose we wish to estimate the proportion of people with diabetes in a population or the proportion of people with hypertension or obesity. These diagnoses are defined by specific levels of laboratory tests and measurements of blood pressure and body mass index, respectively. Subjects are defined as having these diagnoses or not, based on the definitions. When the outcome of interest is dichotomous like this, the record for each member of the sample indicates having the condition or characteristic of interest or not. Recall that for dichotomous outcomes the investigator defines one of the outcomes a "success" and the other a failure. The sample size is denoted by n, and we let x denote the number of "successes" in the sample.
For example, if we wish to estimate the proportion of people with diabetes in a population, we consider a diagnosis of diabetes as a "success" (i.e., and individual who has the outcome of interest), and we consider lack of diagnosis of diabetes as a "failure." In this example, X represents the number of people with a diagnosis of diabetes in the sample. The sample proportion is p̂ (called "p-hat"), and it is computed by taking the ratio of the number of successes in the sample to the sample size, that is:
p̂= x/n
If there are more than 5 successes and more than 5 failures, then the confidence interval can be computed with this formula:
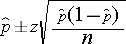
The point estimate for the population proportion is the sample proportion, and the margin of error is the product of the Z value for the desired confidence level (e.g., Z=1.96 for 95% confidence) and the standard error of the point estimate. In other words, the standard error of the point estimate is:
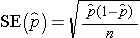
This formula is appropriate for large samples, defined as at least 5 successes and at least 5 failures in the sample. This was a condition for the Central Limit Theorem for binomial outcomes. If there are fewer than 5 successes or failures then alternative procedures, called exact methods, must be used to estimate the population proportion.1,2
Example: During the 7th examination of the Offspring cohort in the Framingham Heart Study there were 1219 participants being treated for hypertension and 2,313 who were not on treatment. If we call treatment a "success", then x=1219 and n=3532. The sample proportion is:
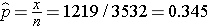
This is the point estimate, i.e., our best estimate of the proportion of the population on treatment for hypertension is 34.5%. The sample is large, so the confidence interval can be computed using the formula:
Substituting our values we get
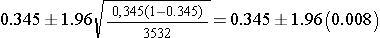
which is
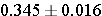
So, the 95% confidence interval is (0.329, 0.361).
Thus we are 95% confident that the true proportion of persons on antihypertensive medication is between 32.9% and 36.1%.
Specific applications of estimation for a single population with a dichotomous outcome involve estimating prevalence, cumulative incidence, and incidence rates.
The table below, from the 5th examination of the Framingham Offspring cohort, shows the number of men and women found with or without cardiovascular disease (CVD). Estimate the prevalence of CVD in men using a 95% confidence interval.
|
|
Free of CVD |
Prevalent CVD |
Total |
|
Men |
1,548 |
244 |
1,792 |
|
Women |
1,872 |
135 |
2,007 |
|
Total |
3,420 |
379 |
3,799 |
Answer
There are many situations where it is of interest to compare two groups with respect to their mean scores on a continuous outcome. For example, we might be interested in comparing mean systolic blood pressure in men and women, or perhaps compare body mass index (BMI) in smokers and non-smokers. Both of these situations involve comparisons between two independent groups, meaning that there are different people in the groups being compared.
We could begin by computing the sample sizes (n1 and n2), means (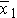 and
and 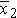 ), and standard deviations (s1 and s2) in each sample.
), and standard deviations (s1 and s2) in each sample.
In the two independent samples application with a continuous outcome, the parameter of interest is the difference in population means, μ1 - μ2. The point estimate for the difference in population means is the difference in sample means:
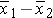
The confidence interval will be computed using either the Z or t distribution for the selected confidence level and the standard error of the point estimate. The use of Z or t again depends on whether the sample sizes are large (n1 > 30 and n2 > 30) or small. The standard error of the point estimate will incorporate the variability in the outcome of interest in each of the comparison groups. If we assume equal variances between groups, we can pool the information on variability (sample variances) to generate an estimate of the population variability. Therefore, the standard error (SE) of the difference in sample means is the pooled estimate of the common standard deviation (Sp) (assuming that the variances in the populations are similar) computed as the weighted average of the standard deviations in the samples, i.e.:
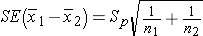
and the pooled estimate of the common standard deviation is
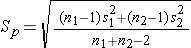
If the sample sizes are larger, that is both n1 and n2 are greater than 30, then one uses the z-table.
If either sample size is less than 30, then the t-table is used.
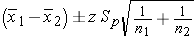
Use Z table for standard normal distribution
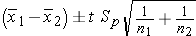
Use the t-table with degrees of freedom = n1+n2-2
For both large and small samples Sp is the pooled estimate of the common standard deviation (assuming that the variances in the populations are similar) computed as the weighted average of the standard deviations in the samples.
These formulas assume equal variability in the two populations (i.e., the population variances are equal, or σ12= σ22), meaning that the outcome is equally variable in each of the comparison populations. For analysis, we have samples from each of the comparison populations, and if the sample variances are similar, then the assumption about variability in the populations is reasonable. As a guideline, if the ratio of the sample variances, s12/s22 is between 0.5 and 2 (i.e., if one variance is no more than double the other), then the formulas in the table above are appropriate. If not, then alternative formulas must be used to account for the heterogeneity in variances.3,4
Large Sample Example:
The table below summarizes data n=3539 participants attending the 7th examination of the Offspring cohort in the Framingham Heart Study.
|
|
Men |
Women |
||||
|
Characteristic |
N |
|
s |
n |
|
s |
|
Systolic Blood Pressure |
1,623 |
128.2 |
17.5 |
1,911 |
126.5 |
20.1 |
|
Diastolic Blood Pressure |
1,622 |
75.6 |
9.8 |
1,910 |
72.6 |
9.7 |
|
Total Serum Cholesterol |
1,544 |
192.4 |
35.2 |
1,766 |
207.1 |
36.7 |
|
Weight |
1,612 |
194.0 |
33.8 |
1,894 |
157.7 |
34.6 |
|
Height |
1,545 |
68.9 |
2.7 |
1,781 |
63.4 |
2.5 |
|
Body Mass Index |
1,545 |
28.8 |
4.6 |
1,781 |
27.6 |
5.9 |
Suppose we want to calculate the difference in mean systolic blood pressures between men and women, and we also want the 95% confidence interval for the difference in means. The sample is large (> 30 for both men and women), so we can use the confidence interval formula with Z. Next, we will check the assumption of equality of population variances. The ratio of the sample variances is 17.52/20.12 = 0.76, which falls between 0.5 and 2, suggesting that the assumption of equality of population variances is reasonable.
First, we need to compute Sp, the pooled estimate of the common standard deviation.
Substituting we get
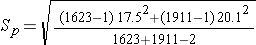
which simplifies to
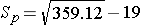
Notice that for this example Sp, the pooled estimate of the common standard deviation, is 19, and this falls in between the standard deviations in the comparison groups (i.e., 17.5 and 20.1). Next we substitute the Z score for 95% confidence, Sp=19, the sample means, and the sample sizes into the equation for the confidence interval.
Substituting
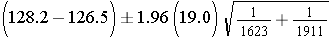
which simplifies to
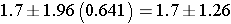
Therefore, the confidence interval is (0.44, 2.96)
Interpretation: With 95% confidence the difference in mean systolic blood pressures between men and women is between 0.44 and 2.96 units. Our best estimate of the difference, the point estimate, is 1.7 units. The standard error of the difference is 0.641, and the margin of error is 1.26 units. Note that when we generate estimates for a population parameter in a single sample (e.g., the mean [μ]) or population proportion [p]) the resulting confidence interval provides a range of likely values for that parameter. In contrast, when comparing two independent samples in this fashion the confidence interval provides a range of values for the difference. In this example, we estimate that the difference in mean systolic blood pressures is between 0.44 and 2.96 units with men having the higher values. In this example, we arbitrarily designated the men as group 1 and women as group 2. Had we designated the groups the other way (i.e., women as group 1 and men as group 2), the confidence interval would have been -2.96 to -0.44, suggesting that women have lower systolic blood pressures (anywhere from 0.44 to 2.96 units lower than men).
The table below summarizes differences between men and women with respect to the characteristics listed in the first column. The second and third columns show the means and standard deviations for men and women respectively. The fourth column shows the differences between males and females and the 95% confidence intervals for the differences.
|
|
Men |
Women |
Difference |
|
Characteristic |
Mean (s) |
Mean (s) |
95% CI |
|
Systolic Blood Pressure |
128.2 (17.5) |
126.5 (20.1) |
(0.44, 2.96) |
|
Diastolic Blood Pressure |
75.6 (9.8) |
72.6 (9.7) |
(2.38, 3.67) |
|
Total Serum Cholesterol |
192.4 (35.2) |
207.1 (36.7) |
(-17.16, -12.24) |
|
Weight |
194.0 (33.8) |
157.7 (34.6) |
(33.98, 38.53) |
|
Height |
68.9 (2.7) |
63.4 (2.5) |
(5.31, 5.66) |
|
Body Mass Index |
28.8 (4.6) |
27.6 (5.9) |
(0.76, 1.48) |
Notice that the 95% confidence interval for the difference in mean total cholesterol levels between men and women is -17.16 to -12.24. Men have lower mean total cholesterol levels than women; anywhere from 12.24 to 17.16 units lower. The men have higher mean values on each of the other characteristics considered (indicated by the positive confidence intervals).
The confidence interval for the difference in means provides an estimate of the absolute difference in means of the outcome variable of interest between the comparison groups. It is often of interest to make a judgment as to whether there is a statistically meaningful difference between comparison groups. This judgment is based on whether the observed difference is beyond what one would expect by chance.
The confidence intervals for the difference in means provide a range of likely values for (μ1-μ2). It is important to note that all values in the confidence interval are equally likely estimates of the true value of (μ1-μ2). If there is no difference between the population means, then the difference will be zero (i.e., (μ1-μ2).= 0). Zero is the null value of the parameter (in this case the difference in means). If a 95% confidence interval includes the null value, then there is no statistically meaningful or statistically significant difference between the groups. If the confidence interval does not include the null value, then we conclude that there is a statistically significant difference between the groups. For each of the characteristics in the table above there is a statistically significant difference in means between men and women, because none of the confidence intervals include the null value, zero. Note, however, that some of the means are not very different between men and women (e.g., systolic and diastolic blood pressure), yet the 95% confidence intervals do not include zero. This means that there is a small, but statistically meaningful difference in the means. When there are small differences between groups, it may be possible to demonstrate that the differences are statistically significant if the sample size is sufficiently large, as it is in this example.
Small Sample Example:
We previously considered a subsample of n=10 participants attending the 7th examination of the Offspring cohort in the Framingham Heart Study. The following table contains descriptive statistics on the same continuous characteristics in the subsample stratified by sex.
|
|
Men |
Women |
||||
|
Characteristic |
n |
Sample Mean |
s |
n |
Sample Mean |
s |
|
Systolic Blood Pressure |
6 |
117.5 |
9.7 |
4 |
126.8 |
12.0 |
|
Diastolic Blood Pressure |
6 |
72.5 |
7.1 |
4 |
69.5 |
8.1 |
|
Total Serum Cholesterol |
6 |
193.8 |
30.2 |
4 |
215.0 |
48.8 |
|
Weight |
6 |
196.9 |
26.9 |
4 |
146.0 |
7.2 |
|
Height |
6 |
70.2 |
1.0 |
4 |
62.6 |
2.3 |
|
Body Mass Index |
6 |
28.0 |
3.6 |
4 |
26.2 |
2.0 |
Suppose we wish to construct a 95% confidence interval for the difference in mean systolic blood pressures between men and women using these data. We will again arbitrarily designate men group 1 and women group 2. Since the sample sizes are small (i.e., n1< 30 and n2< 30), the confidence interval formula with t is appropriate. However,we will first check whether the assumption of equality of population variances is reasonable. The ratio of the sample variances is 9.72/12.02 = 0.65, which falls between 0.5 and 2, suggesting that the assumption of equality of population variances is reasonable. The solution is shown below.
First, we compute Sp, the pooled estimate of the common standard deviation:
Substituting:
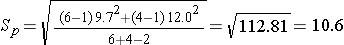
Note that again the pooled estimate of the common standard deviation, Sp, falls in between the standard deviations in the comparison groups (i.e., 9.7 and 12.0). The degrees of freedom (df) = n1+n2-2 = 6+4-2 = 8. From the t-Table t=2.306. The 95% confidence interval for the difference in mean systolic blood pressures is:
Substituting:
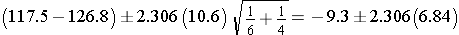
Then simplifying further:
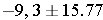
So, the 95% confidence interval for the difference is (-25.07, 6.47)
Interpretation: Our best estimate of the difference, the point estimate, is -9.3 units. The standard error of the difference is 6.84 units and the margin of error is 15.77 units. We are 95% confident that the difference in mean systolic blood pressures between men and women is between -25.07 and 6.47 units. In this sample, the men have lower mean systolic blood pressures than women by 9.3 units. Based on this interval, we also conclude that there is no statistically significant difference in mean systolic blood pressures between men and women, because the 95% confidence interval includes the null value, zero. Again, the confidence interval is a range of likely values for the difference in means. Since the interval contains zero (no difference), we do not have sufficient evidence to conclude that there is a difference. Note also that this 95% confidence interval for the difference in mean blood pressures is much wider here than the one based on the full sample derived in the previous example, because the very small sample size produces a very imprecise estimate of the difference in mean systolic blood pressures.
The previous section dealt with confidence intervals for the difference in means between two independent groups. There is an alternative study design in which two comparison groups are dependent, matched or paired. Consider the following scenarios:
A goal of these studies might be to compare the mean scores measured before and after the intervention, or to compare the mean scores obtained with the two conditions in a crossover study.
Yet another scenario is one in which matched samples are used. For example, we might be interested in the difference in an outcome between twins or between siblings.
Once again we have two samples, and the goal is to compare the two means. However, the samples are related or dependent. In the first scenario, before and after measurements are taken in the same individual. In the last scenario, measures are taken in pairs of individuals from the same family. When the samples are dependent, we cannot use the techniques in the previous section to compare means. Because the samples are dependent, statistical techniques that account for the dependency must be used. These techniques focus on difference scores (i.e., each individual's difference in measures before and after the intervention, or the difference in measures between twins or sibling pairs).
This distinction between independent and dependent samples emphasizes the importance of appropriately identifying the unit of analysis, i.e., the independent entities in a study.
The parameter of interest is the mean difference, μd. Again, the first step is to compute descriptive statistics. We compute the sample size (which in this case is the number of distinct participants or distinct pairs), the mean and standard deviation of the difference scores, and we denote these summary statistics as n, 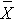 d and sd, respectively. The appropriate formula for the confidence interval for the mean difference depends on the sample size. The formulas are shown in Table 6.5 and are identical to those we presented for estimating the mean of a single sample, except here we focus on difference scores.
d and sd, respectively. The appropriate formula for the confidence interval for the mean difference depends on the sample size. The formulas are shown in Table 6.5 and are identical to those we presented for estimating the mean of a single sample, except here we focus on difference scores.
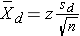
Use Z table for standard normal distribution
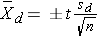
Use t-table with df=n-1
When samples are matched or paired, difference scores are computed for each participant or between members of a matched pair, and "n" is the number of participants or pairs, 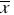 is the mean of the difference scores, and Sd is the standard deviation of the difference scores
is the mean of the difference scores, and Sd is the standard deviation of the difference scores
Example:
In the Framingham Offspring Study, participants attend clinical examinations approximately every four years. Suppose we want to compare systolic blood pressures between examinations (i.e., changes over 4 years). The data below are systolic blood pressures measured at the sixth and seventh examinations in a subsample of n=15 randomly selected participants. Since the data in the two samples (examination 6 and 7) are matched, we compute difference scores by subtracting the blood pressure measured at examination 7 from that measured at examination 6 or vice versa. [If we subtract the blood pressure measured at examination 6 from that measured at examination 7, then positive differences represent increases over time and negative differences represent decreases over time.]
|
Subject # |
Examination 6 |
Examination 7 |
Difference |
|
1 |
168 |
141 |
-27 |
|
2 |
111 |
119 |
8 |
|
3 |
139 |
122 |
-17 |
|
4 |
127 |
127 |
0 |
|
5 |
155 |
125 |
-30 |
|
6 |
115 |
123 |
8 |
|
7 |
125 |
113 |
-12 |
|
8 |
123 |
106 |
-17 |
|
9 |
130 |
131 |
1 |
|
10 |
137 |
142 |
5 |
|
11 |
130 |
131 |
1 |
|
12 |
129 |
135 |
6 |
|
13 |
112 |
119 |
7 |
|
14 |
141 |
130 |
-11 |
|
15 |
122 |
121 |
-1 |
Notice that several participants' systolic blood pressures decreased over 4 years (e.g., participant #1's blood pressure decreased by 27 units from 168 to 141), while others increased (e.g., participant #2's blood pressure increased by 8 units from 111 to 119). We now estimate the mean difference in blood pressures over 4 years. This is similar to a one sample problem with a continuous outcome except that we are now using the difference scores. In this sample, we have n=15, the mean difference score = -5.3 and sd = 12.8, respectively. The calculations are shown below
|
Subject # |
Difference
|
Difference - Mean Difference
|
(Difference - Mean Difference)2
|
|
1 |
-27 |
-21.7 |
470.89 |
|
2 |
8 |
13.3 |
176.89 |
|
3 |
-17 |
-11.7 |
136.89 |
|
4 |
0 |
5.3 |
28.09 |
|
5 |
-30 |
-24.7 |
610.09 |
|
6 |
8 |
13.3 |
176.89 |
|
7 |
-12 |
-6.7 |
44.89 |
|
8 |
-17 |
-11.7 |
136.89 |
|
9 |
1 |
6.3 |
39.69 |
|
10 |
5 |
10.3 |
106.09 |
|
11 |
1 |
6.3 |
39.69 |
|
12 |
6 |
11.3 |
127.69 |
|
13 |
7 |
12.3 |
151.29 |
|
14 |
-11 |
-5.7 |
32.49 |
|
15 |
-1 |
4.3 |
18.49 |
|
|
∑ = -79.0 |
∑ = 0 |
∑ =2296.95 |
Therefore,
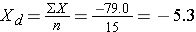
and
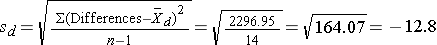
We can now use these descriptive statistics to compute a 95% confidence interval for the mean difference in systolic blood pressures in the population. Because the sample size is small (n=15), we use the formula that employs the t-statistic. The degrees of freedom are df=n-1=14. From the table of t-scores (see Other Resource on the right), t = 2.145. We can now substitute the descriptive statistics on the difference scores and the t value for 95% confidence as follows:
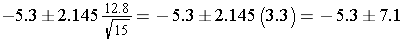
So, the 95% confidence interval for the difference is (-12.4, 1.8).
Interpretation:
We are 95% confident that the mean difference in systolic blood pressures between examinations 6 and 7 (approximately 4 years apart) is between -12.4 and 1.8. The null (or no effect) value of the CI for the mean difference is zero. Therefore, based on the 95% confidence interval we can conclude that there is no statistically significant difference in blood pressures over time, because the confidence interval for the mean difference includes zero.
Crossover trials are a special type of randomized trial in which each subject receives both of the two treatments (e.g., an experimental treatment and a control treatment). Participants are usually randomly assigned to receive their first treatment and then the other treatment. In many cases there is a "wash-out period" between the two treatments. Outcomes are measured after each treatment in each participant. [An example of a crossover trial with a wash-out period can be seen in a study by Pincus et al. in which the investigators compared responses to analgesics in patients with osteoarthritis of the knee or hip.] A major advantage to the crossover trial is that each participant acts as his or her own control, and, therefore, fewer participants are generally required to demonstrate an effect. When the outcome is continuous, the assessment of a treatment effect in a crossover trial is performed using the techniques described here.
Example:
A crossover trial is conducted to evaluate the effectiveness of a new drug designed to reduce symptoms of depression in adults over 65 years of age following a stroke. Symptoms of depression are measured on a scale of 0-100 with higher scores indicative of more frequent and severe symptoms of depression. Patients who suffered a stroke were eligible for the trial. The trial was run as a crossover trial in which each patient received both the new drug and a placebo. Patients were blind to the treatment assignment and the order of treatments (e.g., placebo and then new drug or new drug and then placebo) were randomly assigned. After each treatment, depressive symptoms were measured in each patient. The difference in depressive symptoms was measured in each patient by subtracting the depressive symptom score after taking the placebo from the depressive symptom score after taking the new drug. A total of 100 participants completed the trial and the data are summarized below.
|
|
n |
Mean Difference |
Std. Dev. Difference |
|
Depressive Symptoms After New Drug - Symptoms After Placebo |
100 |
-12.7 |
8.9 |
The mean difference in the sample is -12.7, meaning on average patients scored 12.7 points lower on the depressive symptoms scale after taking the new drug as compared to placebo (i.e., improved by 12.7 points on average). What would be the 95% confidence interval for the mean difference in the population? Since the sample size is large, we can use the formula that employs the Z-score.
Substituting the current values we get
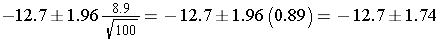
So, the 95% confidence interval is (-14.1, -10.7).
Interpretation: We are 95% confident that the mean improvement in depressive symptoms after taking the new drug as compared to placebo is between 10.7 and 14.1 units (or alternatively the depressive symptoms scores are 10.7 to 14.1 units lower after taking the new drug as compared to placebo). Because we computed the differences by subtracting the scores after taking the placebo from the scores after taking the new drug and because higher scores are indicative of worse or more severe depressive symptoms, negative differences reflect improvement (i.e., lower depressive symptoms scores after taking the new drug as compared to placebo). Because the 95% confidence interval for the mean difference does not include zero, we can conclude that there is a statistically significant difference (in this case a significant improvement) in depressive symptom scores after taking the new drug as compared to placebo.
It is common to compare two independent groups with respect to the presence or absence of a dichotomous characteristic or attribute, (e.g., prevalent cardiovascular disease or diabetes, current smoking status, cancer remission, or successful device implant). When the outcome is dichotomous, the analysis involves comparing the proportions of successes between the two groups. There are several ways of comparing proportions in two independent groups.
Generally the reference group (e.g., unexposed persons, persons without a risk factor or persons assigned to the control group in a clinical trial setting) is considered in the denominator of the ratio. The risk ratio is a good measure of the strength of an effect, while the risk difference is a better measure of the public health impact, because it compares the difference in absolute risk and, therefore provides an indication of how many people might benefit from an intervention. An odds ratio is the measure of association used in case-control studies. It is the ratio of the odds or disease in those with a risk factor compared to the odds of disease in those without the risk factor. When the outcome of interest is relatively uncommon (e.g., <10%), an odds ratio is a good estimate of what the risk ratio would be. The odds are defined as the ratio of the number of successes to the number of failures. All of these measures (risk difference, risk ratio, odds ratio) are used as measures of association by epidemiologists, and these three measures are considered in more detail in the module on Measures of Association in the core course in epidemiology. Confidence interval estimates for the risk difference, the relative risk and the odds ratio are described below.
A risk difference (RD) or prevalence difference is a difference in proportions (e.g., RD = p1-p2) and is similar to a difference in means when the outcome is continuous. The point estimate is the difference in sample proportions, as shown by the following equation:
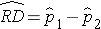
The sample proportions are computed by taking the ratio of the number of "successes" (or health events, x) to the sample size (n) in each group:
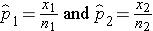 .
.
The formula for the confidence interval for the difference in proportions, or the risk difference, is as follows:
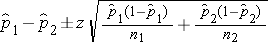
Note that this formula is appropriate for large samples (at least 5 successes and at least 5 failures in each sample). If there are fewer than 5 successes (events of interest) or failures (non-events) in either comparison group, then exact methods must be used to estimate the difference in population proportions.5
Example:
The following table contains data on prevalent cardiovascular disease (CVD) among participants who were currently non-smokers and those who were current smokers at the time of the fifth examination in the Framingham Offspring Study.
|
|
Free of CVD |
History of CVD |
Total |
|
Non-Smoker |
2,757 |
298 |
3,055 |
|
Current Smoker |
663 |
81 |
744 |
|
Total |
3,420 |
379 |
3,799 |
The point estimate of prevalent CVD among non-smokers is 298/3,055 = 0.0975, and the point estimate of prevalent CVD among current smokers is 81/744 = 0.1089. When constructing confidence intervals for the risk difference, the convention is to call the exposed or treated group 1 and the unexposed or untreated group 2. Here smoking status defines the comparison groups, and we will call the current smokers group 1 and the non-smokers group 2. A confidence interval for the difference in prevalent CVD (or prevalence difference) between smokers and non-smokers is given below. In this example, we have far more than 5 successes (cases of prevalent CVD) and failures (persons free of CVD) in each comparison group, so the following formula can be used:
Substituting we get:
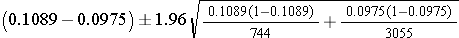
This simplifies to
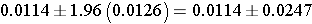
So the 95% confidence interval is (-0.0133, 0.0361),
Interpretation: We are 95% confident that the difference in proportion the proportion of prevalent CVD in smokers as compared to non-smokers is between -0.0133 and 0.0361. The null value for the risk difference is zero. Because the 95% confidence interval includes zero, we conclude that the difference in prevalent CVD between smokers and non-smokers is not statistically significant.
A randomized trial is conducted among 100 subjects to evaluate the effectiveness of a newly developed pain reliever designed to reduce pain in patients following joint replacement surgery. The trial compares the new pain reliever to the pain reliever currently used (the "standard of care"). Patients are randomly assigned to receive either the new pain reliever or the standard pain reliever following surgery. The patients are blind to the treatment assignment. Before receiving the assigned treatment, patients are asked to rate their pain on a scale of 0-10 with high scores indicative of more pain. Each patient is then given the assigned treatment and after 30 minutes is again asked to rate their pain on the same scale. The primary outcome is a reduction in pain of 3 or more scale points (defined by clinicians as a clinically meaningful reduction).
|
Treatment Group |
n |
# with Reduction of 3+ Points |
Proportion with Reduction of 3+ Points |
|
New Pain Reliever |
50 |
23 |
0.46 |
|
Standard Pain Reliever |
50 |
11 |
0.22 |
Answer
The risk difference quantifies the absolute difference in risk or prevalence, whereas the relative risk is, as the name indicates, a relative measure. Both measures are useful, but they give different perspectives on the information. A cumulative incidence is a proportion that provides a measure of risk, and a relative risk (or risk ratio) is computed by taking the ratio of two proportions, p1/p2. By convention we typically regard the unexposed (or least exposed) group as the comparison group, and the proportion of successes or the risk for the unexposed comparison group is the denominator for the ratio. The parameter of interest is the relative risk or risk ratio in the population, RR=p1/p2, and the point estimate is the RR obtained from our samples.
The relative risk is a ratio and does not follow a normal distribution, regardless of the sample sizes in the comparison groups. However, the natural log (Ln) of the sample RR, is approximately normally distributed and is used to produce the confidence interval for the relative risk. Therefore, computing the confidence interval for a risk ratio is a two step procedure. First, a confidence interval is generated for Ln(RR), and then the antilog of the upper and lower limits of the confidence interval for Ln(RR) are computed to give the upper and lower limits of the confidence interval for the RR.
The data can be arranged as follows:
|
|
With Outcome |
Without Outcome |
Total |
|
Exposed Group (1) |
x1 |
n1-x1 |
n1 |
|
Non-exposed Group (2) |
x2 |
n2-x2 |
n2 |
|
|
|
|
|
RR = p1/p2
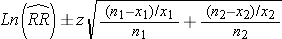
Note that the null value of the confidence interval for the relative risk is one. If a 95% CI for the relative risk includes the null value of 1, then there is insufficient evidence to conclude that the groups are statistically significantly different.
Example:
[Based on Belardinelli R, et al.: "Randomized, Controlled Trial of Long-Term Moderate Exercise Training in Chronic Heart Failure - Effects on Functional Capacity, Quality of Life, and Clinical Outcome". Circulation. 1999;99:1173-1182].
These investigators randomly assigned 99 patients with stable congestive heart failure (CHF) to an exercise program (n=50) or no exercise (n=49) and followed patients twice a week for one year. The outcome of interest was all-cause mortality. Those assigned to the treatment group exercised 3 times a week for 8 weeks, then twice a week for 1 year. Exercise training was associated with lower mortality (9 versus 20) for those with training versus those without.
|
|
Died |
Alive |
Total |
|
Exercised |
9 |
41 |
50 |
|
No Exercise |
20 |
29 |
49 |
|
|
29 |
70 |
99 |
The cumulative incidence of death in the exercise group was 9/50=0.18; in the incidence in the non-exercising group was 20/49=0.4082. Therefore, the point estimate for the risk ratio is RR=p1/p2=0.18/0.4082=0.44. Therefore, exercisers had 0.44 times the risk of dying during the course of the study compared to non-exercisers. We can also interpret this as a 56% reduction in death, since 1-0.44=0.56.
The 95% confidence interval estimate for the relative risk is computed using the two step procedure outlined above.
Substituting, we get:
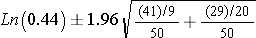
This simplifies to
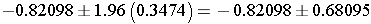
So, the 95% confidence interval is (-1.50193, -0.14003).
A 95% confidence interval for Ln(RR) is (-1.50193, -0.14003). In order to generate the confidence interval for the risk, we take the antilog (exp) of the lower and upper limits:
exp(-1.50193) = 0.2227 and exp(-0.14003) = 0.869331
Interpretation: We are 95% confident that the relative risk of death in CHF exercisers compared to CHF non-exercisers is between 0.22 and 0.87. The null value is 1. Since the 95% confidence interval does not include the null value (RR=1), the finding is statistically significant.
Consider again the randomized trial that evaluated the effectiveness of a newly developed pain reliever for patients following joint replacement surgery. Using the data in the table below, compute the point estimate for the relative risk for achieving pain relief, comparing those receiving the new drug to those receiving the standard pain reliever. Then compute the 95% confidence interval for the relative risk, and interpret your findings in words.
|
Treatment Group |
n |
# with Reduction of 3+ Points |
Proportion with Reduction of 3+ Points |
|
New Pain Reliever |
50 |
23 |
0.46 |
|
Standard Pain Reliever |
50 |
11 |
0.22 |
Answer
In case-control studies it is not possible to estimate a relative risk, because the denominators of the exposure groups are not known with a case-control sampling strategy. Nevertheless, one can compute an odds ratio, which is a similar relative measure of effect.6 (For a more detailed explanation of the case-control design, see the module on case-control studies in Introduction to Epidemiology).
Consider the following hypothetical study of the association between pesticide exposure and breast cancer in a population of 6, 647 people. If data were available on all subjects in the population the the distribution of disease and exposure might look like this:
|
|
Diseased |
Non-diseased |
Total |
|
Pesticide Exposure |
7 |
1,000 |
1,007 |
|
Non-exposed |
6 |
5,634 |
5,640 |
If we had such data on all subjects, we would know the total number of exposed and non-exposed subjects, and within each exposure group we would know the number of diseased and non-disease people, so we could calculate the risk ratio. In this case RR = (7/1,007) / (6/5,640) = 6.52, suggesting that those who had the risk factor (exposure) had 6.5 times the risk of getting the disease compared to those without the risk factor.
However, suppose the investigators planned to determine exposure status by having blood samples analyzed for DDT concentrations, but they only had enough funding for a small pilot study with about 80 subjects in total. The problem, of course, is that the outcome is rare, and if they took a random sample of 80 subjects, there might not be any diseased people in the sample. To get around this problem, case-control studies use an alternative sampling strategy: the investigators find an adequate sample of cases from the source population, and determine the distribution of exposure among these "cases". The investigators then take a sample of non-diseased people in order to estimate the exposure distribution in the total population. As a result, in the hypothetical scenario for DDT and breast cancer the investigators might try to enroll all of the available cases and 67 non-diseased subjects, i.e., 80 in total since that is all they can afford. After the blood samples were analyzed, the results might look like this:
|
|
Diseased |
Non-diseased |
|
|
Pesticide Exposure |
7 |
10 |
|
|
Non-exposed |
6 |
57 |
|
With this sampling approach we can no longer compute the probability of disease in each exposure group, because we just took a sample of the non-diseased subjects, so we no longer have the denominators in the last column. In other words, we don't know the exposure distribution for the entire source population. However, the small control sample of non-diseased subjects gives us a way to estimate the exposure distribution in the source population. So, we can't compute the probability of disease in each exposure group, but we can compute the odds of disease in the exposed subjects and the odds of disease in the unexposed subjects.
The probability that an event will occur is the fraction of times you expect to see that event in many trials.  Probabilities always range between 0 and 1. The odds are defined as the probability that the event will occur divided by the probability that the event will not occur.
Probabilities always range between 0 and 1. The odds are defined as the probability that the event will occur divided by the probability that the event will not occur.
If the probability of an event occurring is Y, then the probability of the event not occurring is 1-Y. (Example: If the probability of an event is 0.80 (80%), then the probability that the event will not occur is 1-0.80 = 0.20, or 20%.
The odds of an event represent the ratio of the (probability that the event will occur) / (probability that the event will not occur). This could be expressed as follows:
Odds of event = Y / (1-Y)
So, in this example, if the probability of the event occurring = 0.80, then the odds are 0.80 / (1-0.80) = 0.80/0.20 = 4 (i.e., 4 to 1).
NOTE that when the probability is low, the odds and the probability are very similar.
With the case-control design we cannot compute the probability of disease in each of the exposure groups; therefore, we cannot compute the relative risk. However, we can compute the odds of disease in each of the exposure groups, and we can compare these by computing the odds ratio. In the hypothetical pesticide study the odds ratio is
OR= (7/10) / (5/57) = 6.65
Notice that this odds ratio is very close to the RR that would have been obtained if the entire source population had been analyzed. The explanation for this is that if the outcome being studied is fairly uncommon, then the odds of disease in an exposure group will be similar to the probability of disease in the exposure group. Consequently, the odds ratio provides a relative measure of effect for case-control studies, and it provides an estimate of the risk ratio in the source population, provided that the outcome of interest is uncommon.
We emphasized that in case-control studies the only measure of association that can be calculated is the odds ratio. However, in cohort-type studies, which are defined by following exposure groups to compare the incidence of an outcome, one can calculate both a risk ratio and an odds ratio.
If we arbitrarily label the cells in a contingency table as follows:
|
|
Diseased |
Non-diseased |
|
|
Exposed |
a |
b |
|
|
Non-exposed |
c |
d |
|
then the odds ratio is computed by taking the ratio of odds, where the odds in each group is computed as follows:
OR = (a/b) / (c/d)
As with a risk ratio, the convention is to place the odds in the unexposed group in the denominator. In addition, like a risk ratio, odds ratios do not follow a normal distribution, so we use the lo g transformation to promote normality. As a result, the procedure for computing a confidence interval for an odds ratio is a two step procedure in which we first generate a confidence interval for Ln(OR) and then take the antilog of the upper and lower limits of the confidence interval for Ln(OR) to determine the upper and lower limits of the confidence interval for the OR. The two steps are detailed below.
To compute the confidence interval for an odds ratio use the formula
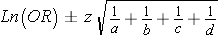
The null, or no difference, value of the confidence interval for the odds ratio is one. If a 95% CI for the odds ratio does not include one, then the odds are said to be statistically significantly different. We again reconsider the previous examples and produce estimates of odds ratios and compare these to our estimates of risk differences and relative risks.
Example:
Consider again the hypothetical pilot study on pesticide exposure and breast cancer:
|
|
Diseased |
Non-diseased |
|
|
Pesticide Exposure |
7 |
10 |
|
|
Non-exposed |
6 |
57 |
|
We noted above that
OR= (7/10) / (5/57) = 6.6
We can compute a 95% confidence interval for this odds ratio as follows:
Substituting we get the following:
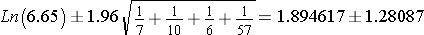
This gives the following interval (0.61, 3.18), but this still need to be transformed by finding their antilog (1.85-23.94) to obtain the 95% confidence interval.
Interpretation: The odds of breast cancer in women with high DDT exposure are 6.65 times greater than the odds of breast cancer in women without high DDT exposure. We are 95% confident that the true odds ratio is between 1.85 and 23.94. The null value is 1, and because this confidence interval does not include 1, the result indicates a statistically significant difference in the odds of breast cancer women with versus low DDT exposure.
Note that an odds ratio is a good estimate of the risk ratio when the outcome occurs relatively infrequently (<10%). Therefore, odds ratios are generally interpreted as if they were risk ratios.
Note also that, while this result is considered statistically significant, the confidence interval is very broad, because the sample size is small. As a result, the point estimate is imprecise. Notice also that the confidence interval is asymmetric, i.e., the point estimate of OR=6.65 does not lie in the exact center of the confidence interval. Remember that we used a log transformation to compute the confidence interval, because the odds ratio is not normally distributed. Therefore, the confidence interval is asymmetric, because we used the log transformation to compute Ln(OR) and then took the antilog to compute the lower and upper limits of the confidence interval for the odds ratio.
Remember that in a true case-control study one can calculate an odds ratio, but not a risk ratio. However, one can calculate a risk difference (RD), a risk ratio (RR), or an odds ratio (OR) in cohort studies and randomized clinical trials. Consider again the data in the table below from the randomized trial assessing the effectiveness of a newly developed pain reliever as compared to the standard of care. Remember that a previous quiz question in this module asked you to calculate a point estimate for the difference in proportions of patients reporting a clinically meaningful reduction in pain between pain relievers as (0.46-0.22) = 0.24, or 24%, and the 95% confidence interval for the risk difference was (6%, 42%). Because the 95% confidence interval for the risk difference did not contain zero (the null value), we concluded that there was a statistically significant difference between pain relievers. Using the same data, we then generated a point estimate for the risk ratio and found RR= 0.46/0.22 = 2.09 and a 95% confidence interval of (1.14, 3.82). Because this confidence interval did not include 1, we concluded once again that this difference was statistically significant. We will now use these data to generate a point estimate and 95% confidence interval estimate for the odds ratio.
We now ask you to use these data to compute the odds of pain relief in each group, the odds ratio for patients receiving new pain reliever as compared to patients receiving standard pain reliever, and the 95% confidence interval for the odds ratio.
|
Treatment Group |
n |
# with Reduction of 3+ Points |
Proportion with Reduction of 3+ Points |
|
New Pain Reliever |
50 |
23 |
0.46 |
|
Standard Pain Reliever |
50 |
11 |
0.22 |
Answer
When the study design allows for the calculation of a relative risk, it is the preferred measure as it is far more interpretable than an odds ratio. The odds ratio is extremely important, however, as it is the only measure of effect that can be computed in a case-control study design. When the outcome of interest is relatively rare (<10%), then the odds ratio and relative risk will be very close in magnitude. In such a case, investigators often interpret the odds ratio as if it were a relative risk (i.e., as a comparison of risks rather than a comparison of odds which is less intuitive).
This module focused on the formulas for estimating different unknown population parameters. In each application, a random sample or two independent random samples were selected from the target population and sample statistics (e.g., sample sizes, means, and standard deviations or sample sizes and proportions) were generated. Point estimates are the best single-valued estimates of an unknown population parameter. Because these can vary from sample to sample, most investigations start with a point estimate and build in a margin of error. The margin of error quantifies sampling variability and includes a value from the Z or t distribution reflecting the selected confidence level as well as the standard error of the point estimate. It is important to remember that the confidence interval contains a range of likely values for the unknown population parameter; a range of values for the population parameter consistent with the data. It is also possible, although the likelihood is small, that the confidence interval does not contain the true population parameter. This is important to remember in interpreting intervals. Confidence intervals are also very useful for comparing means or proportions and can be used to assess whether there is a statistically meaningful difference. This is based on whether the confidence interval includes the null value (e.g., 0 for the difference in means, mean difference and risk difference or 1 for the relative risk and odds ratio).
The precision of a confidence interval is defined by the margin of error (or the width of the interval). A larger margin of error (wider interval) is indicative of a less precise estimate. For example, suppose we estimate the relative risk of complications from an experimental procedure compared to the standard procedure of 5.7. This estimate indicates that patients undergoing the new procedure are 5.7 times more likely to suffer complications. Suppose that the 95% confidence interval is (0.4, 12.6). The confidence interval suggests that the relative risk could be anywhere from 0.4 to 12.6 and because it includes 1 we cannot conclude that there is a statistically significantly elevated risk with the new procedure. Suppose the same study produced an estimate of a relative risk of 2.1 with a 95% confidence interval of (1.5, 2.8). This second study suggests that patients undergoing the new procedure are 2.1 times more likely to suffer complications. However, because the confidence interval here does not contain the null value 1, we can conclude that this is a statistically elevated risk. We will discuss this idea of statistical significance in much more detail in Chapter 7.
The following summary provides the key formulas for confidence interval estimates in different situations.
For n > 30 use the z-table with this equation :
For n<30 use the t-table with degrees of freedom (df)=n-1
If n1 > 30 and n2 > 30, use the z-table with this equation:
If n1 < 30 or n2 < 30, use the t-table with degrees of freedom = n1+n2-2.
For both large and small samples Sp is the pooled estimate of the common standard deviation (assuming that the variances in the populations are similar) computed as the weighted average of the standard deviations in the samples.
If n > 30, use and use the z-table for standard normal distribution
If n < 30, use the t-table with degrees of freedom (df)=n-1
RR = p1/p2
Then take exp[lower limit of Ln(RR)] and exp[upper limit of Ln(RR)] to get the lower and upper limits of the confidence interval for RR.
Then take exp[lower limit of Ln(OR)] and exp[upper limit of Ln(OR)] to get the lower and upper limits of the confidence interval for OR.
Note that this summary table only provides formulas for larger samples. As noted throughout the modules alternative formulas must be used for small samples.
What is the 90% confidence interval for BMI? (Note that Z=1.645 to reflect the 90% confidence level.)
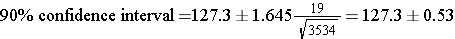
So, the 90% confidence interval is (126.77, 127.83)
=======================================================
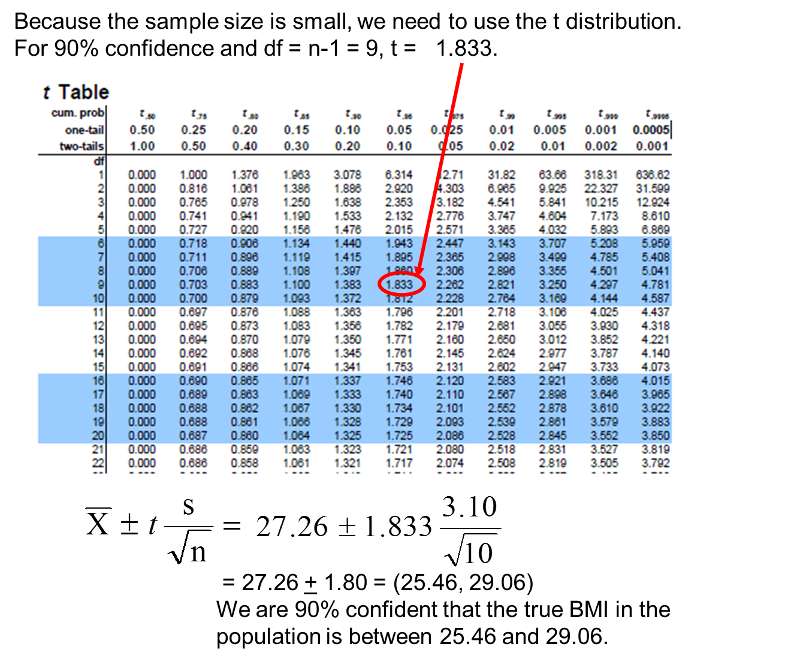
Answer to BMI Problem on page 3
Question: Using the subsample in the table above, what is the 90% confidence interval for BMI?
Solution: Once again, the sample size was 10, so we go to the t-table and use the row with 10 minus 1 degrees of freedom (so 9 degrees of freedom). But now you want a 90% confidence interval, so you would use the column with a two-tailed probability of 0.10. Looking down to the row for 9 degrees of freedom, you get a t-value of 1.833.
Once again you will use this equation:
Plugging in the values for this problem we get the following expression:
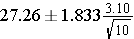
Therefore the 90% confidence interval ranges from 25.46 to 29.06.
=======================================================
The table below, from the 5th examination of the Framingham Offspring cohort, shows the number of men and women found with or without cardiovascular disease (CVD). Estimate the prevalence of CVD in men using a 95% confidence interval.
|
|
Free of CVD |
Prevalent CVD |
Total |
|
Men |
1,548 |
244 |
1,792 |
|
Women |
1,872 |
135 |
2,007 |
|
Total |
3,420 |
379 |
3,799 |
The prevalence of cardiovascular disease (CVD) among men is 244/1792=0.1362. The sample size is large and satisfies the requirement that the number of successes is greater than 5 and the number of failures is greater than 5. Therefore, the following formula can be used again.
Substituting, we get
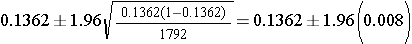
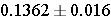
So, the 95% confidence interval is (0.120, 0.152).
With 95% confidence the prevalence of cardiovascular disease in men is between 12.0 to 15.2%.
=======================================================
The point estimate for the difference in proportions is (0.46-0.22)=0.24. Note that the new treatment group is group 1, and the standard treatment group is group 2. Therefore, 24% more patients reported a meaningful reduction in pain with the new drug compared to the standard pain reliever. Since there are more than 5 events (pain relief) and non-events (absence of pain relief) in each group, the large sample formula using the z-score can be used.
Substituting we get
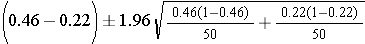
This further simplifies to
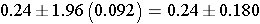
So, the 96% confidence interval for this risk difference is (0.06, 0.42).
Interpretation: Our best estimate is an increase of 24% in pain relief with the new treatment, and with 95% confidence, the risk difference is between 6% and 42%. Since the 95% confidence interval does not contain the null value of 0, we can conclude that there is a statistically significant improvement with the new treatment.
=======================================================
Consider again the randomized trial that evaluated the effectiveness of a newly developed pain reliever for patients following joint replacement surgery. Using the data in the table below, compute the point estimate for the relative risk for achieving pain relief, comparing those receiving the new drug to those receiving the standard pain reliever. Then compute the 95% confidence interval for the relative risk, and interpret your findings in words.
|
Treatment Group |
n |
# with Reduction of 3+ Points |
Proportion with Reduction of 3+ Points |
|
New Pain Reliever |
50 |
23 |
0.46 |
|
Standard Pain Reliever |
50 |
11 |
0.22 |
The point estimate for the relative risk is
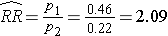
Patients receiving the new drug are 2.09 times more likely to report a meaningful reduction in pain compared to those receivung the standard pain reliever. The 95% confidence interval estimate can be computed in two steps as follows:
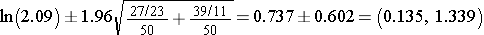
This is the confidence interval for ln(RR). To compute the upper and lower limits for the confidence interval for RR we must find the antilog using the (exp) function:
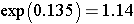
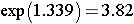
Therefore, we are 95% confident that patients receiving the new pain reliever are between 1.14 and 3.82 times as likely to report a meaningful reduction in pain compared to patients receiving tha standard pain reliever.
===========================================
We now ask you to use these data to compute the odds of pain relief in each group, the odds ratio for patients receiving new pain reliever as compared to patients receiving standard pain reliever, and the 95% confidence interval for the odds ratio.
|
Treatment Group |
n |
# with Reduction of 3+ Points |
Proportion with Reduction of 3+ Points |
|
New Pain Reliever |
50 |
23 |
0.46 |
|
Standard Pain Reliever |
50 |
11 |
0.22 |
It is easier to solve this problem if the information is organized in a contingency table in this way:
|
|
Pain Relief 3+ |
Less Relief |
|---|---|---|
|
New Drug |
23 |
27 |
|
Standard Drug |
11 |
39 |
Odds of pain relief 3+ with new drug = 23/27 0.8519
Odds of pain relief 3+ with standard drug = 11/39 = 0.2821
Odds Ratio = 0.8519 / 0.2821 = 3.02
To compute the 95% confidence interval for the odds ratio we use
Substituting we get
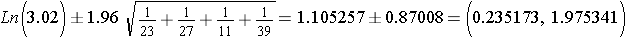
Since we used the log (Ln), we now need to take the antilog to get the limits of the confidente interval.
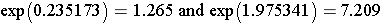
The point estimate of the odds ratio is OR=3.2, and we are 95% confident that the true odds ratio lies between 1.27 and 7.21. This is statistically significant because the 95% confidence interval does not include the null value (OR=1.0).
Note also that the odds rato was greater than the risk ratio for the same problem. For mathematical reasons the odds ratio tends to exaggerate associates when the outcome is more common.
Consider again the randomized trial that evaluated the effectiveness of a newly developed pain reliever for patients following joint replacement surgery. Using the data in the table below, compute the point estimate for the relative risk for achieving pain relief, comparing those receiving the new drug to those receiving the standard pain reliever. Then compute the 95% confidence interval for the relative risk, and interpret your findings in words.
|
Treatment Group |
n |
# with Reduction of 3+ Points |
Proportion with Reduction of 3+ Points |
|
New Pain Reliever |
50 |
23 |
0.46 |
|
Standard Pain Reliever |
50 |
11 |
0.22 |