


Selection Bias in Cohort Studies
1. Subject Selection Bias
Factors affecting enrollment of subjects into a prospective cohort study would not be expected to introduce selection bias. In order for bias to occur, selection has to be related to both exposure and outcome. Subjects are enrolled in prospective cohort studies before they have experienced the outcome of interest. Therefore, while it is easy to see how enrollment might be related to exposure (exposed might be more or less likely to enroll), it is difficult to imagine how either investigators or enrollees could be influenced by awareness of an outcome that hasn't yet occurred.
This form of selection bias could be more common in a retrospective cohort study, especially if individuals have to provide informed consent for participation. Since a retrospective cohort study starts after all cases of disease have occurred, subjects generally would know both their exposure and outcome status. It is not hard to imagine that those with the most interest in participation would both have been exposed and have the disease, a dynamic that would only be accentuated if the study question were a controversial one and/or there were potential liability and monetary consequences tied to the results of the study. Another less common mechanism of selection bias in a retrospective cohort study might occur if retention or loss of records of study subjects (e.g., employment, medical) were related to both exposure and outcome status.
Selection bias can occur if selection or choice of the exposed or unexposed subjects in a retrospective cohort study is somehow related to the outcome of interest.
Example:
Consider a hypothetical investigation of an occupational exposure (e.g., an organic solvent) that occurred 15-20 years ago in factory. Over the years there were suspicions that working eith the solvent led to adverse health events, but no definitive data existed. Eventually, a retrospective cohort study was conducted using the employee health records. If all records had been retained the results might have looked like those shown in the first contingency table below.
|
Unbiased Results |
Diseased |
Non-diseased |
Totaal |
|---|---|---|---|
|
Solvent exposure |
100 |
900 |
1000 |
|
Unexposed |
50 |
950 |
1000 |
This unbiased data would give a risk ratio as follows:

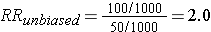
However, suppose that many of the old records had been lost or discarded, but,given the suspicions about the effects of the solvent, the records of employees who had worked with the solvents and subequently had health problems were more likely to be retained. Consequently, record retention was 99% among workers who were exposed and developed health problems, but recorded retention was only 80% for all other workers. This scenario would result in data shown in the next contingency table.
|
Biased Results |
Diseased |
Non-diseased |
Totaal |
|---|---|---|---|
|
Solvent exposure |
99 |
720 |
819 |
|
Unexposed |
40 |
760 |
800 |
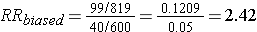
Differential loss of records results in selection bias and an overestimate of the association in this case, although depending on the scenario, this type of selection bias could also result in an underestimate of an associaton.
Prospective cohort studies will not have selection bias as they enroll subjects, because the outcomes are unknown at the beginning of a prospective cohort study. However, prosective cohort studies may have differential retention of subjects over time that is somehow related to exposure status and outcome, and this differential loss to follow up is also a type of selection bias that is analagous to what we saw above in the retrospective study on solvents in a factory..
2. Loss to Follow Up Bias
As noted above, the enrollment of subjects will not bias a prospective cohort study, because the outcome has not yet occurred. Therefore, choice cannot be related to both exposure status and outcome status. However, retention of subjects may be differentially related to exposure and outcome, and this has a similar effect that can bias the results, causing either an overestimate or an underestimate of an association. In the hypothetical cohort study below investigators compared the incidence of thromboembolism (TE) in 10,000 women on oral contraceptives (OC) and 10,000 women not taking OC. TE occurred in 20 subjects taking OC and in 10 subjects not taking OC, so the true risk ratio was (20/10,000) / (10/10,000) = 2.
|
Unbiased Results |
Thromboembolism |
Non-diseased |
Totaal |
|---|---|---|---|
|
Oral Contraceptives |
20 |
9980 |
10,000 |
|
Unexposed |
10 |
9990 |
10,000 |
This unbiased data would give a risk ratio as follows:
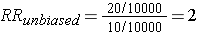
However, suppose there were substantial loses to follow-up in both groups, and a greater tendency to loose subjects taking oral contraceptives who developed thromboembolism. In other words, there was differential loss to follow up with loss of 12 diseased subjects in the group taking oral contraceptives, but loss of only 2 subjects with thromboembolism in the unexposed group. This might result in a contingency table like the one shown below.
|
Biased Results |
Thromboembolism |
Non-diseased |
Totaal |
|---|---|---|---|
|
Oral Contraceptives |
8 |
5980 |
5988 |
|
Unexposed |
8 |
5984 |
5992 |
This biased data would give a risk ratio as follows:
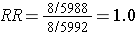
So, in this scenario both exposure groups lost about 40% of their subjects during the follow up period, but there was a greater loss of diseased subjects in the exposed group than in the unexposed group, and it was this differential loss to followup that biased the results.
|
Selection Bias |
Diseased |
Non-diseased |
|---|---|---|
|
Exposed |
|
|
|
Non-exposed |
|
|
Again, depending on which category is underreported as a result of differential loss to follow-up, either an underestimate or overestimate of effect (association) can occur.
Preventing Loss to Follow-up

The only way to prevent bias from loss to follow-up is to maintain high follow up rates (>80%). This can be achieved by:
- Enrolling motivated subjects
- Using subjects who are easy to track
- Making questionnaires as easy to complete as possible
- Maintaining the interest of participants and making them feel that the study is important
- Providing incentives
3. The "Healthy Worker" Effect
The "health worker" effect is really a special type of selection bias that occurs in cohort studies of occupational exposures when the general population is used as the comparison group. The general population consists of both healthy people and unhealthy people. Those who are not healthy are less likely to be employed, while the employed work force tends to have fewer sick people. Moreover, people with severe illnesses would be most likely to be excluded from employment, but not from the general population. As a result, comparisons of mortality rates between an employed group and the general population will be biased.
Suppose, for example, that a given occupational exposure truly increases the risk of death by 20% (RR=1.2). Suppose also that the general population has an overall risk of death that is 10% higher than that of the employed workforce. Given this scenario, use of the general population as a comparison group would result in a underestimate of the risk ratio, i.e. RR=1.1.
Another possibility is that the exposure being tested is not associated with any difference in risk of death (i.e., true RR=1.0). If the general population is used as a comparison group the estimated RR might be around 0.9. Aschengrau and Seage cite a report (Link to report) that found a 16% lower mortality rate (standardized mortality rate = 0.84 in radiation-exposed workers at the Portsmouth Shipyard. It was noted, however, that the radiation workers had to undergo a special physical examination in order to be eligible to work in this particular program. Consequently, it is likely that their baseline health was significantly better than that of the population at large.