


A Nested Case-Control Study
Suppose a prospective cohort study were conducted among almost 90,000 women for the purpose of studying the determinants of cancer and cardiovascular disease. After enrollment, the women provide baseline information on a host of exposures, and they also provide baseline blood and urine samples that are frozen for possible future use. The women are then followed, and, after about eight years, the investigators want to test the hypothesis that past exposure to pesticides such as DDT is a risk factor for breast cancer. Eight years have passed since the beginning of the study, and 1.439 women in the cohort have developed breast cancer. Since they froze blood samples at baseline, they have the option of analyzing all of the blood samples in order to ascertain exposure to DDT at the beginning of the study before any cancers occurred. The problem is that there are almost 90,000 women and it would cost $20 to analyze each of the blood samples. If the investigators could have analyzed all 90,000 samples this is what they would have found the results in the table below.
Table of Breast Cancer Occurrence Among Women With or Without DDT Exposure
|
|
Breast Cancer |
No Breast Cancer |
Total |
|---|---|---|---|
|
DDT exposed |
360 |
13,276 |
13,636 |
|
Unexposed |
1,079 |
75,234 |
76,313 |
|
|
1,439 |
88,510 |
89,949 |
Hypothetical: 
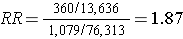
If they had been able to afford analyzing all of the baseline blood specimens in order to categorize the women as having had DDT exposure or not, they would have found a risk ratio = 1.87 (95% confidence interval: 1.66-2.10). The problem is that this would have cost almost $1.8 million, and the investigators did not have the funding to do this.
While 1,439 breast cancers is a disturbing number, it is only 1.6% of the entire cohort, so the outcome is relatively rare, and it is costing a lot of money to analyze the blood specimens obtained from all of the non-diseased women. There is, however, another more efficient alternative, i.e., to use a case-control sampling strategy. One could analyze all of the blood samples from women who had developed breast cancer, but only a sample of the whole cohort in order to estimate the exposure distribution in the population that produced the cases.
If one were to analyze the blood samples of 2,878 of the non-diseased women (twice as many as the number of cases), one would obtain results that would look something like those in the next table.
Table of Breast Cancer Occurrence Among Women With or Without DDT Exposure
|
|
Breast Cancer |
No Breast Cancer |
|---|---|---|
|
DDT exposed |
360 |
432 |
|
Unexposed |
1,079 |
2,446 |
|
|
1,439 |
2,878 |
Odds of Exposure: 360/1079 in the cases versus 432/2,446 in the non-diseased controls.
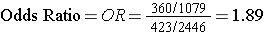
Totals Samples analyzed = 1,438+2,878 = 4,316
Total Cost = 4,316 x $20 = $86,320
With this approach a similar estimate of risk was obtained after analyzing blood samples from only a small sample of the entire population at a fraction of the cost with hardly any loss in precision. In essence, a case-control strategy was used, but it was conducted within the context of a prospective cohort study. This is referred to as a case-control study "nested" within a cohort study.
Rothman states that one should look upon all case-control studies as being "nested" within a cohort. In other words the cohort represents the source population that gave rise to the cases. With a case-control sampling strategy one simply takes a sample of the population in order to obtain an estimate of the exposure distribution within the population that gave rise to the cases. Obviously, this is a much more efficient design.
It is important to note that, unlike cohort studies, case-control studies do not follow subjects through time. Cases are enrolled at the time they develop disease and controls are enrolled at the same time. The exposure status of each is determined, but they are not followed into the future for further development of disease.
As with cohort studies, case-control studies can be prospective or retrospective. At the start of the study, all cases might have already occurred and then this would be a retrospective case-control study. Alternatively, none of the cases might have already occurred, and new cases will be enrolled prospectively. Epidemiologists generally prefer the prospective approach because it has fewer biases, but it is more expensive and sometimes not possible. When conducted prospectively, or when nested in a prospective cohort study, it is straightforward to select controls from the population at risk. However, in retrospective case-control studies, it can be difficult to select from the population at risk, and controls are then selected from those in the population who didn't develop disease. Using only the non-diseased to select controls as opposed to the whole population means the denominator is not really a measure of disease frequency, but when the disease is rare, the odds ratio using the non-diseased will be very similar to the estimate obtained when the entire population is used to sample for controls. This phenomenon is known as the rare-disease assumption. When case-control studies were first developed, most were conducted retrospectively, and it is sometimes assumed that the rare-disease assumption applies to all case-control studies. However, it actually only applies to those case-control studies in which controls are sampled only from the non-diseased rather than the whole population.
The difference between sampling from the whole population and only the non-diseased is that the whole population contains people both with and without the disease of interest. This means that a sampling strategy that uses the whole population as its source must allow for the fact that people who develop the disease of interest can be selected as controls. Students often have a difficult time with this concept. It is helpful to remember that it seems natural that the population denominator includes people who develop the disease in a cohort study. If a case-control study is a more efficient way to obtain the information from a cohort study, then perhaps it is not so strange that the denominator in a case-control study also can include people who develop the disease. This topic is covered in more detail in EP813 Intermediate Epidemiology.
Retrospective and Prospective Case-Control Studies
Students usually think of case-control studies as being only retrospective, since the investigators enroll subjects who have developed the outcome of interest. However, case-control studies, like cohort studies, can be either retrospective or prospective. In a prospective case-control study, the investigator still enrolls based on outcome status, but the investigator must wait to the cases to occur.