


Tests with One Sample, Discrete Outcome
Here we consider hypothesis testing with a discrete outcome variable in a single population. Discrete variables are variables that take on more than two distinct responses or categories and the responses can be ordered or unordered (i.e., the outcome can be ordinal or categorical). The procedure we describe here can be used for dichotomous (exactly 2 response options), ordinal or categorical discrete outcomes and the objective is to compare the distribution of responses, or the proportions of participants in each response category, to a known distribution. The known distribution is derived from another study or report and it is again important in setting up the hypotheses that the comparator distribution specified in the null hypothesis is a fair comparison. The comparator is sometimes called an external or a historical control.
In one sample tests for a discrete outcome, we set up our hypotheses against an appropriate comparator. We select a sample and compute descriptive statistics on the sample data. Specifically, we compute the sample size (n) and the proportions of participants in each response
category ( 
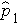 ,
, 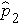 , ...
, ... 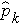 ) where k represents the number of response categories. We then determine the appropriate test statistic for the hypothesis test. The formula for the test statistic is given below.
) where k represents the number of response categories. We then determine the appropriate test statistic for the hypothesis test. The formula for the test statistic is given below.
Test Statistic for Testing H0: p1 = p 10 , p2 = p 20 , ..., pk = p k0
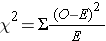
We find the critical value in a table of probabilities for the chi-square distribution with degrees of freedom (df) = k-1. In the test statistic, O = observed frequency and E=expected frequency in each of the response categories. The observed frequencies are those observed in the sample and the expected frequencies are computed as described below. χ2 (chi-square) is another probability distribution and ranges from 0 to ∞. The test above statistic formula above is appropriate for large samples, defined as expected frequencies of at least 5 in each of the response categories.
When we conduct a χ2 test, we compare the observed frequencies in each response category to the frequencies we would expect if the null hypothesis were true. These expected frequencies are determined by allocating the sample to the response categories according to the distribution specified in H0. This is done by multiplying the observed sample size (n) by the proportions specified in the null hypothesis (p 10 , p 20 , ..., p k0 ). To ensure that the sample size is appropriate for the use of the test statistic above, we need to ensure that the following: min(np10 , n p20 , ..., n pk0 ) > 5.
The test of hypothesis with a discrete outcome measured in a single sample, where the goal is to assess whether the distribution of responses follows a known distribution, is called the χ2 goodness-of-fit test. As the name indicates, the idea is to assess whether the pattern or distribution of responses in the sample "fits" a specified population (external or historical) distribution. In the next example we illustrate the test. As we work through the example, we provide additional details related to the use of this new test statistic.
Example:
A University conducted a survey of its recent graduates to collect demographic and health information for future planning purposes as well as to assess students' satisfaction with their undergraduate experiences. The survey revealed that a substantial proportion of students were not engaging in regular exercise, many felt their nutrition was poor and a substantial number were smoking. In response to a question on regular exercise, 60% of all graduates reported getting no regular exercise, 25% reported exercising sporadically and 15% reported exercising regularly as undergraduates. The next year the University launched a health promotion campaign on campus in an attempt to increase health behaviors among undergraduates. The program included modules on exercise, nutrition and smoking cessation. To evaluate the impact of the program, the University again surveyed graduates and asked the same questions. The survey was completed by 470 graduates and the following data were collected on the exercise question:
|
|
No Regular Exercise |
Sporadic Exercise |
Regular Exercise |
Total |
|
Number of Students |
255 |
125 |
90 |
470 |
Based on the data, is there evidence of a shift in the distribution of responses to the exercise question following the implementation of the health promotion campaign on campus? Run the test at a 5% level of significance.
In this example, we have one sample and a discrete (ordinal) outcome variable (with three response options). We specifically want to compare the distribution of responses in the sample to the distribution reported the previous year (i.e., 60%, 25%, 15% reporting no, sporadic and regular exercise, respectively). We now run the test using the five-step approach.
- Step 1. Set up hypotheses and determine level of significance.
The null hypothesis again represents the "no change" or "no difference" situation. If the health promotion campaign has no impact then we expect the distribution of responses to the exercise question to be the same as that measured prior to the implementation of the program.
H0: p1=0.60, p2=0.25, p3=0.15, or equivalently H0: Distribution of responses is 0.60, 0.25, 0.15
H1: H0 is false. α =0.05
Notice that the research hypothesis is written in words rather than in symbols. The research hypothesis as stated captures any difference in the distribution of responses from that specified in the null hypothesis. We do not specify a specific alternative distribution, instead we are testing whether the sample data "fit" the distribution in H0 or not. With the χ2 goodness-of-fit test there is no upper or lower tailed version of the test.
- Step 2. Select the appropriate test statistic.
The test statistic is:
We must first assess whether the sample size is adequate. Specifically, we need to check min(np0, np1, ..., n pk) > 5. The sample size here is n=470 and the proportions specified in the null hypothesis are 0.60, 0.25 and 0.15. Thus, min( 470(0.65), 470(0.25), 470(0.15))=min(282, 117.5, 70.5)=70.5. The sample size is more than adequate so the formula can be used.
- Step 3. Set up decision rule.
The decision rule for the χ2 test depends on the level of significance and the degrees of freedom, defined as degrees of freedom (df) = k-1 (where k is the number of response categories). If the null hypothesis is true, the observed and expected frequencies will be close in value and the χ2 statistic will be close to zero. If the null hypothesis is false, then the χ2 statistic will be large. Critical values can be found in a table of probabilities for the χ2 distribution. Here we have df=k-1=3-1=2 and a 5% level of significance. The appropriate critical value is 5.99, and the decision rule is as follows: Reject H0 if χ2 > 5.99.
- Step 4. Compute the test statistic.
We now compute the expected frequencies using the sample size and the proportions specified in the null hypothesis. We then substitute the sample data (observed frequencies) and the expected frequencies into the formula for the test statistic identified in Step 2. The computations can be organized as follows.
|
|
No Regular Exercise |
Sporadic Exercise |
Regular Exercise |
Total |
|---|---|---|---|---|
|
Observed Frequencies (O) |
255 |
125 |
90 |
470 |
|
Expected Frequencies (E) |
470(0.60) =282 |
470(0.25) =117.5 |
470(0.15) =70.5 |
470 |
Notice that the expected frequencies are taken to one decimal place and that the sum of the observed frequencies is equal to the sum of the expected frequencies. The test statistic is computed as follows:
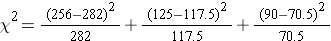
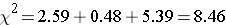
- Step 5. Conclusion.
We reject H0 because 8.46 > 5.99. We have statistically significant evidence at α=0.05 to show that H0 is false, or that the distribution of responses is not 0.60, 0.25, 0.15. The p-value is p < 0.005.
In the χ2 goodness-of-fit test, we conclude that either the distribution specified in H0 is false (when we reject H0) or that we do not have sufficient evidence to show that the distribution specified in H0 is false (when we fail to reject H0). Here, we reject H0 and concluded that the distribution of responses to the exercise question following the implementation of the health promotion campaign was not the same as the distribution prior. The test itself does not provide details of how the distribution has shifted. A comparison of the observed and expected frequencies will provide some insight into the shift (when the null hypothesis is rejected). Does it appear that the health promotion campaign was effective?
Consider the following:
|
|
No Regular Exercise |
Sporadic Exercise |
Regular Exercise |
Total |
|---|---|---|---|---|
|
Observed Frequencies (O) |
255 |
125 |
90 |
470 |
|
Expected Frequencies (E) |
282 |
117.5 |
70.5 |
470 |
If the null hypothesis were true (i.e., no change from the prior year) we would have expected more students to fall in the "No Regular Exercise" category and fewer in the "Regular Exercise" categories. In the sample, 255/470 = 54% reported no regular exercise and 90/470=19% reported regular exercise. Thus, there is a shift toward more regular exercise following the implementation of the health promotion campaign. There is evidence of a statistical difference, is this a meaningful difference? Is there room for improvement?
Example:
The National Center for Health Statistics (NCHS) provided data on the distribution of weight (in categories) among Americans in 2002. The distribution was based on specific values of body mass index (BMI) computed as weight in kilograms over height in meters squared. Underweight was defined as BMI< 18.5, Normal weight as BMI between 18.5 and 24.9, overweight as BMI between 25 and 29.9 and obese as BMI of 30 or greater. Americans in 2002 were distributed as follows: 2% Underweight, 39% Normal Weight, 36% Overweight, and 23% Obese. Suppose we want to assess whether the distribution of BMI is different in the Framingham Offspring sample. Using data from the n=3,326 participants who attended the seventh examination of the Offspring in the Framingham Heart Study we created the BMI categories as defined and observed the following:
|
|
Underweight BMI<18.5 |
Normal Weight BMI 18.5-24.9 |
Overweight BMI 25.0-29.9 |
Obese BMI > 30 |
Total |
|---|---|---|---|---|---|
|
# of Participants |
20 |
932 |
1374 |
1000 |
3326 |
- Step 1. Set up hypotheses and determine level of significance.
H0: p1=0.02, p2=0.39, p3=0.36, p4=0.23 or equivalently
H0: Distribution of responses is 0.02, 0.39, 0.36, 0.23
H1: H0 is false. α=0.05
- Step 2. Select the appropriate test statistic.
The formula for the test statistic is:
We must assess whether the sample size is adequate. Specifically, we need to check min(np0, np1, ..., n pk) > 5. The sample size here is n=3,326 and the proportions specified in the null hypothesis are 0.02, 0.39, 0.36 and 0.23. Thus, min( 3326(0.02), 3326(0.39), 3326(0.36), 3326(0.23))=min(66.5, 1297.1, 1197.4, 765.0)=66.5. The sample size is more than adequate, so the formula can be used.
- Step 3. Set up decision rule.
Here we have df=k-1=4-1=3 and a 5% level of significance. The appropriate critical value is 7.81 and the decision rule is as follows: Reject H0 if χ2 > 7.81.
- Step 4. Compute the test statistic.
We now compute the expected frequencies using the sample size and the proportions specified in the null hypothesis. We then substitute the sample data (observed frequencies) into the formula for the test statistic identified in Step 2. We organize the computations in the following table.
|
|
Underweight BMI<18.5 |
Normal BMI 18.5-24.9 |
Overweight BMI 25.0-29.9 |
Obese BMI > 30 |
Total |
|---|---|---|---|---|---|
|
Observed Frequencies (O) |
20 |
932 |
1374 |
1000 |
3326 |
|
Expected Frequencies (E) |
66.5 |
1297.1 |
1197.4 |
765.0 |
3326 |
The test statistic is computed as follows:
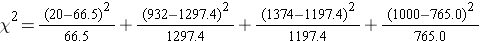
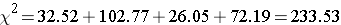
- Step 5. Conclusion.
We reject H0 because 233.53 > 7.81. We have statistically significant evidence at α=0.05 to show that H0 is false or that the distribution of BMI in Framingham is different from the national data reported in 2002, p < 0.005.
Again, the χ2 goodness-of-fit test allows us to assess whether the distribution of responses "fits" a specified distribution. Here we show that the distribution of BMI in the Framingham Offspring Study is different from the national distribution. To understand the nature of the difference we can compare observed and expected frequencies or observed and expected proportions (or percentages). The frequencies are large because of the large sample size, the observed percentages of patients in the Framingham sample are as follows: 0.6% underweight, 28% normal weight, 41% overweight and 30% obese. In the Framingham Offspring sample there are higher percentages of overweight and obese persons (41% and 30% in Framingham as compared to 36% and 23% in the national data), and lower proportions of underweight and normal weight persons (0.6% and 28% in Framingham as compared to 2% and 39% in the national data). Are these meaningful differences?
In the module on hypothesis testing for means and proportions, we discussed hypothesis testing applications with a dichotomous outcome variable in a single population. We presented a test using a test statistic Z to test whether an observed (sample) proportion differed significantly from a historical or external comparator. The chi-square goodness-of-fit test can also be used with a dichotomous outcome and the results are mathematically equivalent.
In the prior module, we considered the following example. Here we show the equivalence to the chi-square goodness-of-fit test.
Example:
The NCHS report indicated that in 2002, 75% of children aged 2 to 17 saw a dentist in the past year. An investigator wants to assess whether use of dental services is similar in children living in the city of Boston. A sample of 125 children aged 2 to 17 living in Boston are surveyed and 64 reported seeing a dentist over the past 12 months. Is there a significant difference in use of dental services between children living in Boston and the national data?
We presented the following approach to the test using a Z statistic.
- Step 1. Set up hypotheses and determine level of significance
H0: p = 0.75
H1: p ≠ 0.75 α=0.05
- Step 2. Select the appropriate test statistic.
We must first check that the sample size is adequate. Specifically, we need to check min(np0, n(1-p0)) = min( 125(0.75), 125(1-0.75))=min(94, 31)=31. The sample size is more than adequate so the following formula can be used
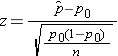
- Step 3. Set up decision rule.
This is a two-tailed test, using a Z statistic and a 5% level of significance. Reject H0 if Z < -1.960 or if Z > 1.960.
- Step 4. Compute the test statistic.
We now substitute the sample data into the formula for the test statistic identified in Step 2. The sample proportion is:
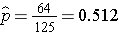
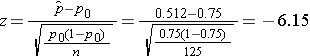
![]()
- Step 5. Conclusion.
We reject H0 because -6.15 < -1.960. We have statistically significant evidence at a =0.05 to show that there is a statistically significant difference in the use of dental service by children living in Boston as compared to the national data. (p < 0.0001).
We now conduct the same test using the chi-square goodness-of-fit test. First, we summarize our sample data as follows:
|
|
Saw a Dentist in Past 12 Months |
Did Not See a Dentist in Past 12 Months |
Total |
|---|---|---|---|
|
# of Participants |
64 |
61 |
125 |
- Step 1. Set up hypotheses and determine level of significance.
H0: p1=0.75, p2=0.25 or equivalently H0: Distribution of responses is 0.75, 0.25
H1: H0 is false. α=0.05
- Step 2. Select the appropriate test statistic.
The formula for the test statistic is:
We must assess whether the sample size is adequate. Specifically, we need to check min(np0, np1, ...,npk>) > 5. The sample size here is n=125 and the proportions specified in the null hypothesis are 0.75, 0.25. Thus, min( 125(0.75), 125(0.25))=min(93.75, 31.25)=31.25. The sample size is more than adequate so the formula can be used.
- Step 3. Set up decision rule.
Here we have df=k-1=2-1=1 and a 5% level of significance. The appropriate critical value is 3.84, and the decision rule is as follows: Reject H0 if χ2 > 3.84. (Note that 1.962 = 3.84, where 1.96 was the critical value used in the Z test for proportions shown above.)
- Step 4. Compute the test statistic.
We now compute the expected frequencies using the sample size and the proportions specified in the null hypothesis. We then substitute the sample data (observed frequencies) into the formula for the test statistic identified in Step 2. We organize the computations in the following table.
|
|
Saw a Dentist in Past 12 Months |
Did Not See a Dentist in Past 12 Months |
Total |
|---|---|---|---|
|
Observed Frequencies (O) |
64 |
61 |
125 |
|
Expected Frequencies (E) |
93.75 |
31.25 |
125 |
The test statistic is computed as follows:
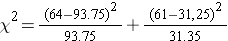
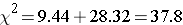
(Note that (-6.15)2 = 37.8, where -6.15 was the value of the Z statistic in the test for proportions shown above.)
- Step 5. Conclusion.
We reject H0 because 37.8 > 3.84. We have statistically significant evidence at α=0.05 to show that there is a statistically significant difference in the use of dental service by children living in Boston as compared to the national data. (p < 0.0001). This is the same conclusion we reached when we conducted the test using the Z test above. With a dichotomous outcome, Z2 = χ2 ! In statistics, there are often several approaches that can be used to test hypotheses.